

在这篇博客中,我将详细介绍如何实现Raft分布式共识算法的核心功能,包括领导人选举、日志复制和提交等等。
实验准备
http://nil.csail.mit.edu/6.5840/2024/labs/lab-raft.html
Debug日志
前言
尽管Raft是一个相对好理解的分布式共识算法,但Raft仍然是一个复杂的分布式系统。而调试一个分布式系统是一项非常难的任务。
我们可以在代码中加入调试日志代码,但密密麻麻日志非常容易使我们头脑混乱,严重影响调试效率,而在完成Lab3的过程中,我们大部分时间都将花费在Debug中(至少我花费了大量时间)。
参考《Debugging by Pretty Printing》 ,我们可以将日志更直观地输出在终端,方便我们快速定位问题,如下图所示。
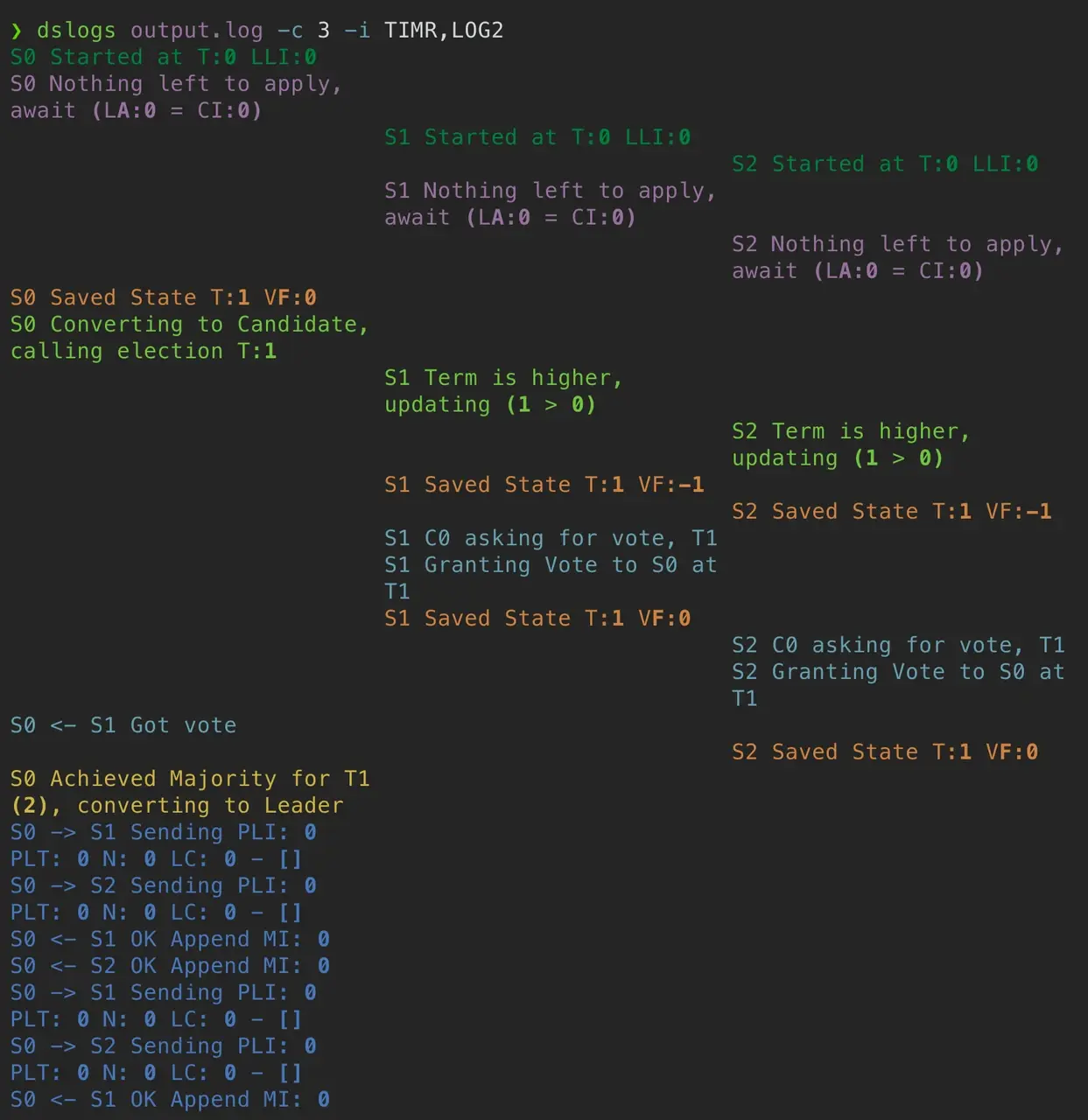
实现
在src/raft/utils.go中,添加如下代码:
var (
debugStart time.Time
debugVerbosity int
)
func init() {
debugStart = time.Now()
debugVerbosity = getVerbosity()
// 将日志的输出格式修改为不包含日期和时间戳。
log.SetFlags(log.Flags() &^ (log.Ldate | log.Ltime))
}
type logTopic string
const (
dClient logTopic = "CLNT"
dCommit logTopic = "CMIT"
dDrop logTopic = "DROP"
dError logTopic = "ERRO"
dInfo logTopic = "INFO"
dLeader logTopic = "LEAD"
dLog logTopic = "LOG1"
dLog2 logTopic = "LOG2"
dPersist logTopic = "PERS"
dSnap logTopic = "SNAP"
dTerm logTopic = "TERM"
dTest logTopic = "TEST"
dTimer logTopic = "TIMR"
dTrace logTopic = "TRCE"
dVote logTopic = "VOTE"
dWarn logTopic = "WARN"
)
func DebugPrintf(topic logTopic, serverId int, format string, a ...interface{}) {
if debugVerbosity >= 1 {
t := time.Since(debugStart).Microseconds()
t /= 100
prefix := fmt.Sprintf("%06d %v S%d ", t, string(topic), serverId)
format = prefix + format
log.Printf(format, a...)
}
}
func getVerbosity() int {
v := os.Getenv("VERBOSE")
level := 0
if v != "" {
var err error
level, err = strconv.Atoi(v)
if err != nil {
log.Fatalf("Invalid verbosity %v", v)
}
}
return level
}
然后,我们就可以在代码中编写Debug代码如下:
DebugPrintf(dClient, rf.me, "重置选举时刻")
查看
我们需要实现一个Python脚本美化日志。首先安装rich与typer库。
pip install rich typer
编写以下脚本,与博客中相同,我将脚本命名为dslogs.py,同样放置在src/raft目录下。
import sys
import shutil
from typing import Optional, List, Tuple, Dict
import typer
from rich import print
from rich.columns import Columns
from rich.console import Console
from rich.traceback import install
# fmt: off
# Mapping from topics to colors
TOPICS = {
"TIMR": "#9a9a99",
"VOTE": "#67a0b2",
"LEAD": "#d0b343",
"TERM": "#70c43f",
"LOG1": "#4878bc",
"LOG2": "#398280",
"CMIT": "#98719f",
"PERS": "#d08341",
"SNAP": "#FD971F",
"DROP": "#ff615c",
"CLNT": "#00813c",
"TEST": "#fe2c79",
"INFO": "#ffffff",
"WARN": "#d08341",
"ERRO": "#fe2626",
"TRCE": "#fe2626",
}
# fmt: on
def list_topics(value: Optional[str]):
if value is None:
return value
topics = value.split(",")
for topic in topics:
if topic not in TOPICS:
raise typer.BadParameter(f"topic {topic} not recognized")
return topics
def main(
file: typer.FileText = typer.Argument(None, help="File to read, stdin otherwise"),
colorize: bool = typer.Option(True, "--no-color"),
n_columns: Optional[int] = typer.Option(None, "--columns", "-c"),
ignore: Optional[str] = typer.Option(None, "--ignore", "-i", callback=list_topics),
just: Optional[str] = typer.Option(None, "--just", "-j", callback=list_topics),
):
topics = list(TOPICS)
# We can take input from a stdin (pipes) or from a file
input_ = file if file else sys.stdin
# Print just some topics or exclude some topics (good for avoiding verbose ones)
if just:
topics = just
if ignore:
topics = [lvl for lvl in topics if lvl not in set(ignore)]
topics = set(topics)
console = Console()
width = console.size.width
panic = False
for line in input_:
try:
time, topic, *msg = line.strip().split(" ")
# To ignore some topics
if topic not in topics:
continue
msg = " ".join(msg)
# Debug calls from the test suite aren't associated with
# any particular peer. Otherwise we can treat second column
# as peer id
if topic != "TEST":
i = int(msg[1])
# Colorize output by using rich syntax when needed
if colorize and topic in TOPICS:
color = TOPICS[topic]
msg = f"[{color}]{msg}[/{color}]"
# Single column printing. Always the case for debug stmts in tests
if n_columns is None or topic == "TEST":
print(time, msg)
# Multi column printing, timing is dropped to maximize horizontal
# space. Heavylifting is done through rich.column.Columns object
else:
cols = ["" for _ in range(n_columns)]
msg = "" + msg
cols[i] = msg
col_width = int(width / n_columns)
cols = Columns(cols, width=col_width - 1, equal=True, expand=True)
print(cols)
except:
# Code from tests or panics does not follow format
# so we print it as is
if line.startswith("panic"):
panic = True
# Output from tests is usually important so add a
# horizontal line with hashes to make it more obvious
if not panic:
print("#" * console.width)
print(line, end="")
if __name__ == "__main__":
typer.run(main)
当我们需要调试测试代码时,可以使用如下命令:
VERBOSE=1 go test -run InitialElection | python dslogs.py -c 3
Lab-3A - 领导人选举
任务要求
3A要求我们实现Raft的Leader选举以及心跳检测功能(无需考虑日志)。3A实验的目标是选举出一个单一的Leader,如果没有故障,Leader将保持领导地位,并且如果旧Leader失败或与旧Leader来往的数据包丢失,则新领导者将接管。运行 go test -run 3A 来测试您的 3A 代码。任务要求给出的提示较多,以下是我抽取的几个比较重要的提示。
提示:
- 按照论文中的图 2。在这一点上,您关心发送和接收 RequestVote RPC,与选举相关的服务器规则以及与领导者选举相关的状态。
- 在 raft.go 中的 Raft 结构体中添加用于领导者选举的图2 状态。您还需要定义一个结构体来保存每个日志条目的信息。
测试器要求:
- 测试器要求Leader每秒钟发送不超过十次心跳 RPC。
- 测试器要求旧Leader失败后的五秒内选出新领导者(如果大多数Server仍然可以通信)。
- 该论文的第 5.2 节提到选举超时范围为 150 至 300 毫秒。只有当领导者发送心跳比每 150 毫秒一次更频繁(例如每 10 毫秒一次)时,这样的范围才有意义。由于测试器每秒只能限制您的心跳数十次,因此您将不得不使用比论文中的 150 至 300 毫秒更长的选举超时时间,但不要太长,否则您可能无法在五秒内选举出领导者。
- 不要忘记实现 GetState() 。
- 测试器在永久关闭实例时会调用您的 Raft 的 rf.Kill() 。您可以使用 rf.killed() 检查是否已调用 Kill() 。您可能希望在所有循环中执行此操作,以避免死亡 Raft 实例打印混淆的消息。
实现
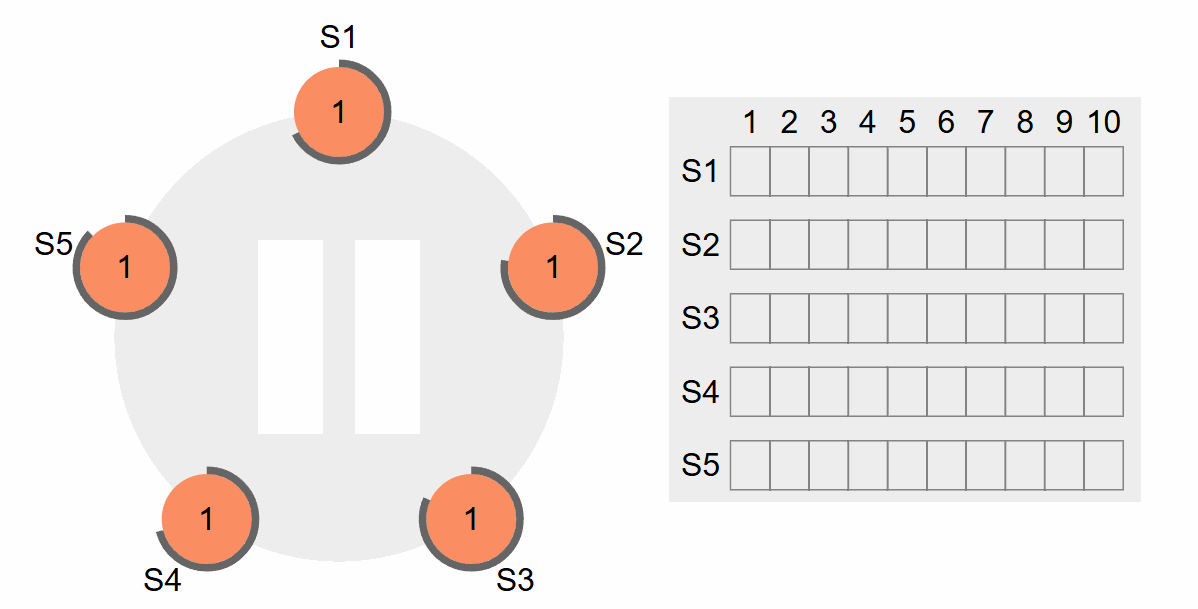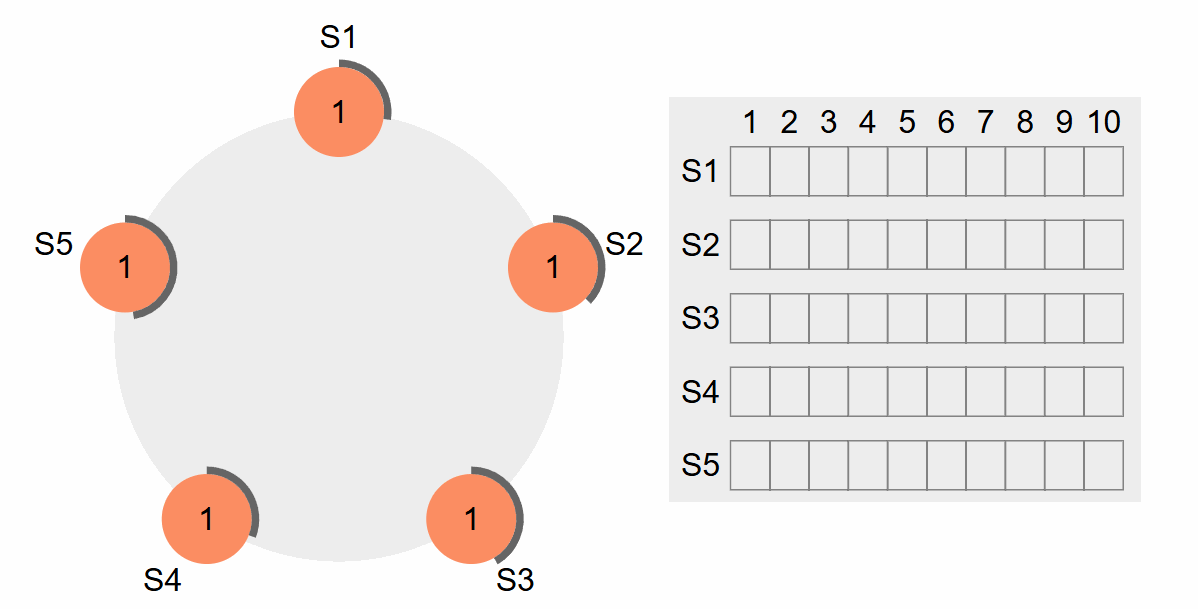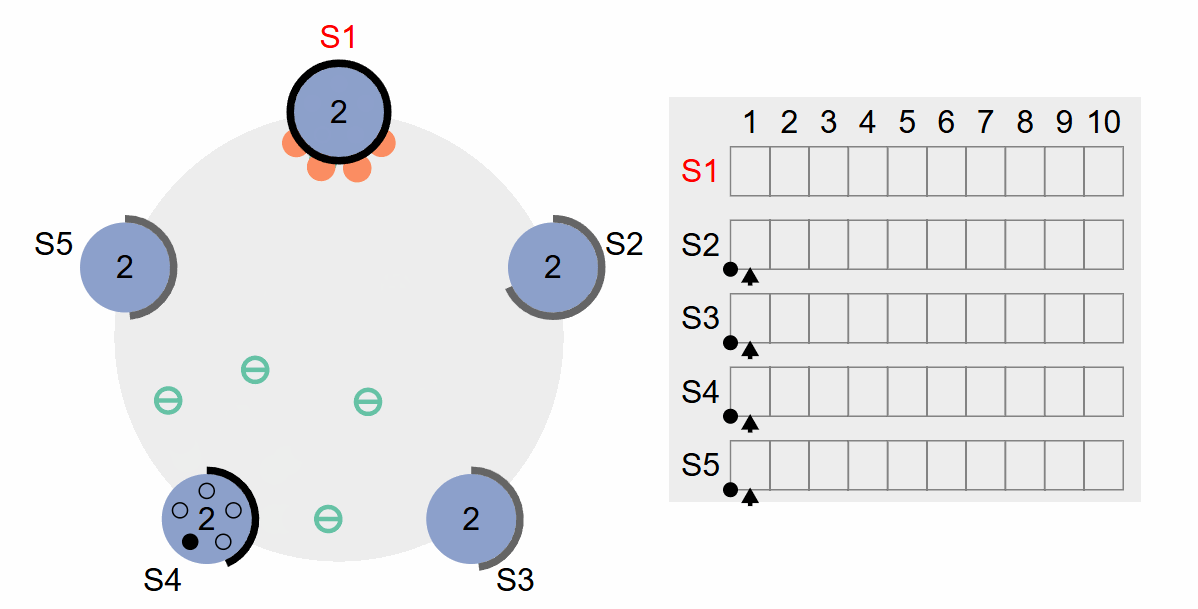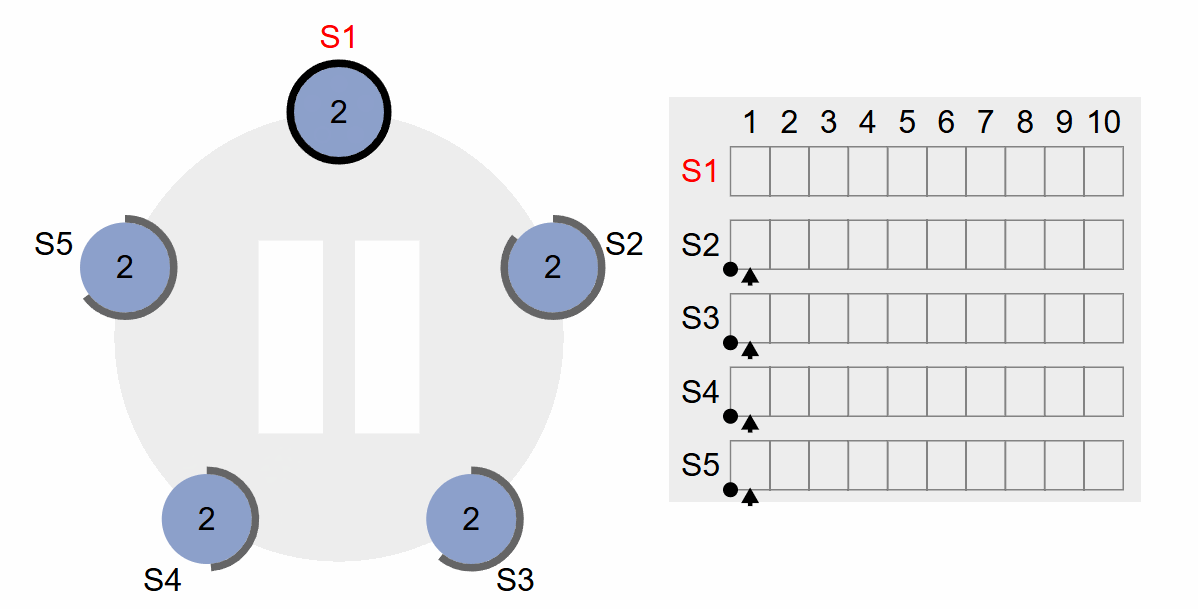
以上动图基本涵盖了领导人选举的步骤,首先各个Server等待选举时间,达到选举时间后,Server转变为Candidate,等待其他Server投票,获得半数以上票数的Server当选为Leader,其他Server转变为Follower。
那么我们需要实现的功能包括“发起选举”、“重置选举时间”、“广播心跳(日志)”、“投票”、“响应Leader”。
常量定义
首先,我们先定义Peer的状态,根据论文中的描述,Server存在Follower、Candidate、Leader三种状态。
type State int
const (
_ State = iota
StateFollower
StateCandidate
StateLeader
)
然后再定义最小心跳间隔以及最小选举间隔。只要系统满足下面的时间要求,Raft可以选举并维持一个稳定的 leader:
广播时间(broadcastTime) « 选举超时时间(electionTimeout) « 平均故障间隔时间(MTBF)
广播时间指的是从一个服务器并行的发送 RPCs 给集群中的其他服务器并接收响应的平均时间;选举超时时间就是在前面介绍的选举的超时时间限制;平均故障间隔时间就是对于一台服务器而言,两次故障之间的平均时间。
测试器要求中已经说明,Leader每秒钟发送不超过10次心跳(或者说广播),因此我将最小心跳间隔定义为100ms,而选举间隔时间应该远大于心跳间隔,但又不宜过长,否则无法在5秒内选举出新的Leader,因此我定义最小选举间隔为500ms。
const (
minHeartBeatInterval = 60 * time.Millisecond
minElectionInterval = 500 * time.Millisecond
)
结构体定义
首先是定义结构体,根据Raft论文中的定义。注意,完成3A任务无需关注Log。
type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
// Your data here (3A, 3B, 3C).
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
state State
heartBeatTime time.Time
electionTime time.Time
// 以下字段论文原文
currentTerm int // 当前任期
votedFor int // 投票给的候选者ID
log []LogEntry // 日志
commitIndex int // 已经提交的最高日志条目索引
lastApplied int // 已经应用到状态机的最高日志条目索引
nextIndex []int // 对每个服务器,要发送的下一跳日志条目的索引
matchIndex []int // 对每个服务器,已知被复制的最高日志条目的索引
}
测试器还要求我们实现GetState()方法,代码如下:
func (rf *Raft) GetState() (int, bool) {
var term int
var isleader bool
// Your code here (3A).
rf.mu.Lock()
defer rf.mu.Unlock()
term = rf.currentTerm
if rf.state == StateLeader {
isleader = true
}
return term, isleader
}
该方法通过获取 currentTerm 和 state 字段的值来获取当前服务器的状态,返回当前任期号和该服务器是否为 leader。
选举和心跳时间重置
如果某一时刻所有Server都发起选举,那么很有可能会发生所有Server都投自己一票,然后拒绝别人的投票,由此将选票瓜分,也称为活锁状态。Raft 算法使用随机选举超时时间(randomized election timeouts)的方法来确保很少会发生选票瓜分的情况,就算发生也能很快的解决:
- 每一个 candidate 在开始一次选举的时候会从一个固定的区间(例如 150-300 毫秒)随机选择一个选举超时时间,然后在超时时间内等待投票的结果。
- 由于一个任期内不能重复投票,越早超时的 candidate 越先开始拉票,也更容易胜出。
我们可以将最大选举时间间隔定义为 最小间隔+(最小间隔 * 0.7),然后随机选取**[最小间隔,最大间隔)**中的值为。而心跳时间固定为100ms一次。定义函数如下:
// 重置选举时间
func (rf *Raft) resetElectionTime() {
now := time.Now()
extra := time.Duration(float64(rand.Int63()%int64(minElectionInterval)) * 0.7)
rf.electionTime = now.Add(minElectionInterval).Add(extra)
}
// 重置心跳时间
func (rf *Raft) resetHeartBeatTime() {
now := time.Now()
rf.heartBeatTime = now.Add(minHeartBeatInterval)
}
定义了结构体与重置函数之后,我们就可以给结构体赋初始值,代码框架中要求我们实现Make函数。如下:
func Make(peers []*labrpc.ClientEnd, me int,
persister *Persister, applyCh chan ApplyMsg) *Raft {
rf := &Raft{}
rf.peers = peers
rf.persister = persister
rf.me = me
// Your initialization code here (3A, 3B, 3C).
rf.state = StateFollower
rf.votedFor = -1
rf.currentTerm = 0
rf.resetElectionTime()
rf.resetHeartBeatTime()
rf.commitIndex = 0
rf.lastApplied = 0
rf.nextIndex = make([]int, len(peers))
rf.matchIndex = make([]int, len(peers))
// initialize from state persisted before a crash
rf.readPersist(persister.ReadRaftState())
// start ticker goroutine to start elections
go rf.ticker()
return rf
}
RPC函数定义
完成Lab3A仅需实现两个RPC函数——RequestVote和AppendEntries。
RequestVote用于候选者请求选举,而AppendEntries用于同步日志以及接收心跳信息。实现3A无需关注日志,因此这里暂且将AppendEntrie视为接收心跳请求。
根据论文,我们先定义出如下请求响应参数。实验代码已经给出了RequsetVote函数的骨架,而AppendEntries需要自行定义。
RequestVote
对于RequesetVote的请求响应。
type RequestVoteArgs struct {
// Your data here (3A, 3B).
Term int // 候选者的任期号
CandidateId int // 候选者ID
LastLogIndex int // 候选者最新日志的索引
LastLogTerm int // 候选者最新日志的任期号
}
type RequestVoteReply struct {
// Your data here (3A).
Term int // 当前任期
VoteGranted bool // 是否投票
}
RequesetVote RPC
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
// Your code here (3A, 3B).
rf.mu.Lock()
defer rf.mu.Unlock()
DebugPrintf(dVote, rf.me, "收到候选人S%d选举请求", args.CandidateId)
if args.Term < rf.currentTerm {
DebugPrintf(dVote, rf.me, "拒绝候选者S%d,任期小于自身", args.CandidateId)
reply.VoteGranted = false
reply.Term = rf.currentTerm
return
}
if args.Term > rf.currentTerm {
rf.state = StateFollower
rf.currentTerm = args.Term
rf.votedFor = -1
}
if rf.votedFor == -1 || rf.votedFor == args.CandidateId {
reply.VoteGranted = true
reply.Term = rf.currentTerm
rf.votedFor = args.CandidateId
DebugPrintf(dVote, rf.me, "选举候选人 S%d", args.CandidateId)
// 重置选举时间
rf.resetElectionTime()
} else {
reply.VoteGranted = false
reply.Term = rf.currentTerm
DebugPrintf(dVote, rf.me, "已选择S%d 拒绝候选人S%d", rf.votedFor, args.CandidateId)
}
}

在该代码中,我们要判断rf.votedFor==-1或者rf.votedFor == args.CandidateId为真时,则投票。假如没有rf.votedFor== args.CandidateId,则可能导致一轮选举无法选出Leader,如上图所示,当S3收到S2选举请求并投票时,S3的votedFor值更改为S2,但S3响应的RPC丢失,此时S2再次发送选举请求,如果没有不判断rf.votedFor == args.CandidateId,则将返回False,很明显就发生了错误,致使无法选举出Leader。
AppendEntries
而对于AppendEntries的请求响应:
type AppendEntriesArgs struct {
Term int
LeaderId int
PrevLogIndex int
PrevLogTerm int
Entries []int
LeaderCommit int
}
type AppendEntriesReply struct {
Term int
Success bool
}
// AppendEntries RPC 发送心跳或者日志提交
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
DebugPrintf(dClient, rf.me, "收到 S%d AppendEntries", args.LeaderId)
rf.mu.Lock()
defer rf.mu.Unlock()
// 如果收到的任期小于自身,则拒绝Leader
if args.Term < rf.currentTerm {
DebugPrintf(dClient, rf.me, "收到的任期号Term%d小于自身任期号Term%d", args.Term, rf.currentTerm)
DebugPrintf(dTerm, rf.me, "当前任期号:%d", rf.currentTerm)
reply.Success = false
reply.Term = rf.currentTerm
return
}
if rf.state == StateCandidate && rf.currentTerm == args.Term {
rf.state = StateFollower
DebugPrintf(dInfo, rf.me, "由候选者降级为追随者")
}
// 收到的任期大于自身,则追随该Leader
if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
// 如果是Leader或候选人,则降级为Follower
if rf.state == StateLeader || rf.state == StateCandidate {
rf.state = StateFollower
DebugPrintf(dClient, rf.me, "收到的新的任期号Term%d,降级为Follower", rf.currentTerm)
}
}
reply.Term = rf.currentTerm
reply.Success = true
rf.resetElectionTime()
}
广播Entries
在Lab3A中,广播Entries用来维护Follower的追随状态,并重置Follower的选举发起时间。
func (rf *Raft) broadcastEntries() {
DebugPrintf(dLeader, rf.me, "开始广播AppendEntries")
for i := 0; i < len(rf.peers); i++ {
if i == rf.me {
continue
}
args := AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
}
go rf.sendEntry2Server(i, args)
}
rf.resetHeartBeatTime()
rf.resetElectionTime()
}
根据论文,当Leader收到了大于自身任期的消息,应该降级为Follower;而当Leader收到了小于自身的任期的消息,应该将该消息视为过期消息而抛弃;当任期相同时,Leader需要将NextIndex值减1,然后再次发送消息给Follower,直到达到一致点。
func (rf *Raft) sendEntry2Server(server int, args AppendEntriesArgs) {
var reply AppendEntriesReply
if !rf.appendEntries(server, &args, &reply) {
return
}
rf.mu.Lock()
defer rf.mu.Unlock()
if reply.Term > rf.currentTerm {
if rf.state == StateLeader {
DebugPrintf(dInfo, rf.me, "Term:%d > CurrentTerm%d,降级为Follower", reply.Term, rf.currentTerm)
rf.state = StateFollower
}
rf.currentTerm = reply.Term
rf.resetElectionTime()
return
}
if rf.state != StateLeader {
DebugPrintf(dWarn, rf.me, "非Leader,拒绝响应 S%d:%d", server, reply.Term)
return
}
if reply.Term < rf.currentTerm {
DebugPrintf(dWarn, rf.me, "响应的任期号%d更小,拒绝接受", reply.Term, rf.currentTerm)
return
}
if reply.Success {
DebugPrintf(dLeader, rf.me, "S%d成功AppendEntry", server)
} else {
DebugPrintf(dLeader, rf.me, "S%d拒绝AppendEntry", server)
}
}
发起选举
发起选举函数包括raiseElection和broadcastElection。raiseElection 方法本质上是一个接口,用于启动 Raft 实例的选举过程。
// 开始选举
func (rf *Raft) raiseElection() {
rf.votedFor = rf.me
rf.state = StateCandidate
rf.currentTerm++
DebugPrintf(dTerm, rf.me, "当前任期号:%d", rf.currentTerm)
DebugPrintf(dVote, rf.me, "发起选举")
// 构建rpc请求与响应
args := RequestVoteArgs{
Term: rf.currentTerm,
CandidateId: rf.me,
}
// 并行发送投票信息
go rf.broadcastElection(args)
//重置选举时间
rf.resetElectionTime()
}
broadcastElection 方法向所有其他节点发送投票请求,以及对投票响应进行处理。
func (rf *Raft) broadcastElection(args RequestVoteArgs) {
ticket := 1
var once sync.Once
for i := 0; i < len(rf.peers); i++ {
if i == rf.me {
continue
}
go func(server int) {
var reply RequestVoteReply
if !rf.sendRequestVote(server, &args, &reply) {
// 发送选取请求失败
return
}
rf.mu.Lock()
defer rf.mu.Unlock()
if reply.VoteGranted && reply.Term == rf.currentTerm {
ticket++
// 如果票数超过半数,则晋升Leader
if ticket > (len(rf.peers)-1)>>1 {
// 确保每次晋升Leader只执行一次
once.Do(func() {
DebugPrintf(dLeader, rf.me, "升级为Leader")
DebugPrintf(dTerm, rf.me, "当前任期号:%d", rf.currentTerm)
rf.state = StateLeader
rf.broadcastEntries() // 当选之后立马发送Entries
})
}
}
}(i)
}
}
注意,当追随者(启动时所有Peer均为追随者)决定发起选举时,应该立即转换状态,将自身的任期值Term加1,并投票给自己。候选者收到超过半数的选票时(包括投给自己的选票),将晋升为Leader。broadcastElection函数中,每次收到Vote RPC的响应时,要判断Peer是否投票以及任期是否与候选者对应。晋升后立即发送一次心跳请求,要求其余Peer成为追随者。
完成Ticker()和Kill()
我们需要监听是否达到心跳时间与选举时间,一种方案是启动对应的协程一直监听,当时间点达到时触发响应的任务。但任务提示中建议我们不要使用 Go 的 time.Timer 或 time.Ticker ,因为这些很难正确使用,而给出了Ticker方法的骨架,那么我们就按照任务提示进行。
使用Ticker方法无法保证时刻达到时立即触发任务,每轮检测之后都需要进行50~350ms的休眠,但这并不影响Raft的实现。
注意,在实现Raft过程中会经常使用锁,锁保证peer状态的正确性,要防止出现死锁问题。
func (rf *Raft) ticker() {
for rf.killed() == false {
// Your code here (3A)
// Check if a leader election should be started.
// 如果当前阶段为Leader,并且达到心跳时间
rf.mu.Lock()
if rf.state == StateLeader && time.Now().After(rf.heartBeatTime) {
rf.sendHeartBeat()
}
rf.mu.Unlock()
// 达到选举时间
rf.mu.Lock()
if time.Now().After(rf.electionTime) {
rf.raiseElection()
}
rf.mu.Unlock()
// pause for a random amount of time between 50 and 350
// milliseconds.
ms := 50 + (rand.Int63() % 300)
time.Sleep(time.Duration(ms) * time.Millisecond)
}
}
Kill函数我们只进行简单的日志打印。
func (rf *Raft) Kill() {
atomic.StoreInt32(&rf.dead, 1)
// Your code here, if desired.
DebugPrintf(dWarn, rf.me, "Killed")
}
运行结果
=== RUN TestInitialElection3A
Test (3A): initial election ...
... Passed -- 3.5 3 26 5236 0
--- PASS: TestInitialElection3A (3.54s)
=== RUN TestReElection3A
Test (3A): election after network failure ...
... Passed -- 5.1 3 60 9308 0
--- PASS: TestReElection3A (5.10s)
=== RUN TestManyElections3A
Test (3A): multiple elections ...
... Passed -- 7.1 7 300 46506 0
--- PASS: TestManyElections3A (7.13s)
PASS
ok 6.5840/raft 15.783s
Lab-3B - 日志
任务要求
实现领导者和追随者代码以附加新的日志条目,以便 go test -run 3B 测试通过。
提示:
- 你的第一个目标应该是通过 TestBasicAgree3B() 。首先实现 Start() ,然后编写代码通过 AppendEntries RPC 发送和接收新的日志条目,遵循图 2。在每个Peer节点上通过 applyCh 发送每个新提交的条目。
- 您需要实现选举限制(论文中的 5.4.1 节)。
- 您的代码可能有循环,重复检查某些事件。不要让这些循环连续执行而不暂停,因为这会使您的实现变慢,从而无法通过测试。使用 Go 的条件变量,或在每个循环迭代中插入 time.Sleep(10 * time.Millisecond) 。
- 为了未来的实验,请自己做个好事,编写(或重新编写)干净、清晰的代码。有关想法,请重新访问我们的指南页面 ,其中提供了有关如何开发和调试代码的提示。
实现——准备步骤
工具函数
实现max和min工具函数将有助于代码实现,不过Go 1.21.0版本已经内置了max和min。
func max(a, b int) int {
if a >= b {
return a
}
return b
}
func min(a, b int) int {
if a <= b {
return a
}
return b
}
定义LogEntry
该实现需要实现日志同步,那么需要先定义一下LogEntry结构体。max和min方法后续会用到。
type LogEntry struct {
Term int //创建该Log时的任期
Command interface{} //需要执行的命令
}
此外,我们还需要定义一些辅助方法便于我们获取操作Log。
// GetLogSlice [i,j)
func (rf *Raft) GetLogSlice(left, right int) []LogEntry {
if left > right {
panic("left > right")
}
if left < 1 || right > rf.LastLogIndex()+1 {
panic("数组越界")
}
newLog := make([]LogEntry, right-left)
copy(newLog, rf.log[left-1:right-1])
return newLog
}
func (rf *Raft) LastLogIndex() int {
idx := len(rf.log)
return idx
}
func (rf *Raft) LastLogTerm() int {
entry := rf.GetLog(rf.LastLogIndex())
return entry.Term
}
func (rf *Raft) GetLog(index int) LogEntry {
idx := index
if idx < 0 {
log.Panicf("idx:%d < 0", idx)
}
if idx > len(rf.log) {
return LogEntry{
Term: 0,
Command: nil,
}
}
return rf.log[idx-1]
}
补充结构体
定义完日志后,我们需要将其补充至Raft结构体中。
type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
// Your data here (3A, 3B, 3C).
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
state State
heartBeatTime time.Time
electionTime time.Time
// 以下字段论文原文
log []LogEntry
currentTerm int // 当前任期
votedFor int // 投票给的候选者ID
commitIndex int // 已经提交的最高日志条目索引
lastApplied int // 已经应用到状态机的最高日志条目索引
nextIndex []int // 对每个服务器,要发送的下一跳日志条目的索引
matchIndex []int // 对每个服务器,已知被复制的最高日志条目的索引
}
此外,我们需要将AppendEntriesArgs结构体中的Entries字段更换为LogEntry切片。
type AppendEntriesArgs struct {
Term int
LeaderId int
PrevLogIndex int
PrevLogTerm int
Entries []LogEntry
LeaderCommit int
}
实现Start方法
Start方法用于Server接收命令。
如果该Server不是 Leader,它将返回false。如果该Server是Leader,则开始共识过程并立即返回。但是需要注意,无法保证此命令将被提交到 Raft 日志中,因为 Leader 可能会失败或失去选举。但即使 Raft 实例已经停止运行,此函数也应该正常返回。
Start方法第一个返回值是该命令在日志中可能出现的索引。第二个返回值是当前任期号。第三个返回值是true,表示该服务器认为它是 Leader。注意,该方法由Tester执行。
func (rf *Raft) Start(command interface{}) (int, int, bool) {
index := -1
term := -1
isLeader := true
// Your code here (3B).
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.state != StateLeader {
return -1, -1, false
}
DebugPrintf(dInfo, rf.me, "收到Tester传来的Command: { %v }", command)
rf.log = append(rf.log, LogEntry{
Term: rf.currentTerm,
Command: command,
})
term = rf.currentTerm
index = rf.LastLogIndex() // 日志索引从1开始
isLeader = true
// 发送AppendEntry
rf.broadcastEntries()
return index, term, isLeader
}
提交日志commitMsg
Raft节点本身是没有状态机实现的,状态机应该由Raft的上层应用来实现。因此,在MIT6.5840-3B实验中,我们无需考虑状态机的实现,只需将日志发送给Make函数的applyCh入参通道来模拟提交。为了方便控制,我们需要实现一个commitMsg方法,将已经commit的数据模拟提交至状态机。
论文中要求我们根据lastApplied参数与commitIndex参数控制提交,为了防止代码阻塞造成占锁时间过长,可以先将msg添加到数组中,再遍历数组发送给applyCh通道,代码如下:
func (rf *Raft) commitMsg(applyCh chan ApplyMsg) {
for !rf.killed() {
msg := make([]ApplyMsg, 0, rf.commitIndex-rf.lastApplied+1)
rf.mu.Lock()
// lastApplied为索引号,从1开始
for rf.lastApplied < rf.commitIndex {
rf.lastApplied++
msg = append(msg, ApplyMsg{
CommandValid: true,
Command: rf.GetLog(rf.lastApplied).Command,
CommandIndex: rf.lastApplied,
})
}
rf.mu.Unlock()
for _, v := range msg {
DebugPrintf(dCommit, rf.me, "提交 {Index:%d , Cmd: %v}至ApplyCh", v.CommandIndex, v.Command)
applyCh <- v
}
ms := 20
time.Sleep(time.Duration(ms) * time.Millisecond)
}
}
该函数无法一直加锁到ApplyMsg都提交至applyCh,会造成死锁现象。
完成以上工作,接下来需要修改Make函数。我们需要新增一个协程运行commitMsg方法,还需要初始化rf.log参数。注意,索引与论文一致,都默认从1开始。
func Make(peers []*labrpc.ClientEnd, me int,
persister *Persister, applyCh chan ApplyMsg) *Raft {
rf := &Raft{}
rf.peers = peers
rf.persister = persister
rf.me = me
// Your initialization code here (3A, 3B, 3C).
rf.log = make([]LogEntry, 0) // new 初始化log
rf.state = StateFollower
rf.votedFor = -1
rf.currentTerm = 0
rf.resetElectionTime()
rf.resetHeartBeatTime()
rf.commitIndex = 0
rf.lastApplied = 0
rf.nextIndex = make([]int, len(peers))
rf.matchIndex = make([]int, len(peers))
go rf.commitMsg(applyCh) // new 提交msg
// initialize from state persisted before a crash
rf.readPersist(persister.ReadRaftState())
// start ticker goroutine to start elections
go rf.ticker()
return rf
}
实现——核心步骤
以下是论文中要求**节点要遵守的规则,**这些规则将会指导我们完成Lab-3B。
所有节点:
- 如果
commitIndex > lastApplied,则 lastApplied 递增,并将log[lastApplied]应用到状态机中(对应Lab3中的上传至applyCh通道)。 - 如果接收到的 RPC 请求或响应中,任期号
T > currentTerm,则令currentTerm = T,并切换为跟随者状态。
follower:
- 响应来自候选人和领导人的请求。
- 如果选举时间超时后,没有收到当前领导人的
AppendEntries RPC,或者没有给某个候选人投过票,就自己变成候选人。
candidate:
- 在转变成候选人后就立即开始选举过程:自增当前的任期号
currentTerm,给自己投票,重置选举超时计时器,发送请求投票的 RPC 给其他所有服务器。 - 如果接收到超过半数Server的选票,那么就变成Leader。
- 如果接收到来自新的Leader的附加日志
AppendEntries RPC,则转变成Follower。 - 如果选举过程超时,则再次发起一轮选举。
leader:
- 一旦成为领导人:发送空的
AppendEntries RPC给其他所有的Server;在一定的空余时间之后不停的重复发送,以防止 follower 超时。 - 如果接收到来自客户端的请求:附加Entry到本地日志中,在Entry被应用到状态机后响应客户端。
- 对于Follower,如果 leader 最后一项 log entry 的索引值=
nextIndex,则发送从 nextIndex 开始的所有 log entry:如果成功,更新相应跟随者的 nextIndex 和 matchIndex;如果因为日志不一致而失败,则 nextIndex 递减并重试。 - 假设存在 N 满足
N > commitIndex,使得大多数的matchIndex[i] ≥ N以及log[N].term == currentTerm成立,则令commitIndex = N。
初始选举参数
按照论文,当Follower升级为Candidate之后,需要初始化NextIndex与MatchIndex。
NextIndex表示要发送的下一个日志条目的索引(索引由1开始);MatchIndex表示被复制的最高日志条目的索引。初始时,NextIndex的值均为【Leader最长日志索引+1】,而MatchIndex均为0。
然后,我们需要为LastLogIndex与LastLogTerm赋值,这些参数将作为其他Server投票的依据。LastLogIndex表示最后一条日志的索引,而LastLogTerm为最后一条日志索引的任期值。当不存在日志时,LastLogIndex将为初始值0,同样的,LastLogTerm也将为初始值0。
由此,我们需要修改raiseElection()方法。
func (rf *Raft) raiseElection() {
rf.votedFor = rf.me
rf.state = StateCandidate
rf.currentTerm++
// 升级为Candidate之后,需要更新MatchIndex、NextIndex
for k := range rf.nextIndex {
//初始时,nextIndex为最后日志索引 + 1,如果索引由1开始,那么log数组的长度即最后日志索引
rf.nextIndex[k] = rf.LastLogIndex() + 1
//初始时,matchIndex均为0
rf.matchIndex[k] = 0
}
DebugPrintf(dTerm, rf.me, "当前任期号:%d", rf.currentTerm)
DebugPrintf(dVote, rf.me, "发起选举")
// 构建rpc请求与响应
var (
lastLogIndex int
lastLogTerm int
)
lastLogIndex = rf.LastLogIndex()
if lastLogIndex != 0 {
lastLogTerm = rf.LastLogTerm()
}
args := RequestVoteArgs{
Term: rf.currentTerm,
CandidateId: rf.me,
LastLogIndex: lastLogIndex,
LastLogTerm: lastLogTerm,
}
// 并行发送投票信息
go rf.broadcastElection(args)
//重置选举时间
rf.resetElectionTime()
}
补充broadcastEntries方法
在Lab3A中,我们定义了broadcastEntries方法,该方法向各Follower发送心跳信息,底层使用AppendEntries接口,但该接口不仅接受心跳信息,同样负责日志同步问题。因此,我们需要补充broadcastEntries方法。
func (rf *Raft) broadcastEntries() {
DebugPrintf(dLeader, rf.me, "开始广播AppendEntries")
for i := 0; i < len(rf.peers); i++ {
if i == rf.me {
continue
}
var (
prevLogIndex int
prevLogTerm int
entries []LogEntry
)
prevLogIndex = rf.nextIndex[i] - 1
if rf.nextIndex[i]-1 != 0 {
prevLogTerm = rf.GetLog(prevLogIndex).Term
}
// 剩余log未提交,则附加Entries
if rf.LastLogIndex() >= rf.nextIndex[i] {
entries = rf.GetLogSlice(rf.nextIndex[i], rf.LastLogIndex()+1)
DebugPrintf(dInfo, rf.me, "For S%d, Append Entiries: %d, nextIdx:%d", i, len(entries), rf.nextIndex[i])
}
args := AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
PrevLogIndex: prevLogIndex,
PrevLogTerm: prevLogTerm,
LeaderCommit: rf.commitIndex,
Entries: entries,
}
go rf.sendEntry2Server(i, args)
}
rf.resetHeartBeatTime()
rf.resetElectionTime()
}
PrevLogIndex表示前一个日志索引,由NextIndex决定,当NextIndex为初始情况0时,PrevLogIndex同样为0。prevLogTerm表示前一个日志的任期值,当PrevLogIndex为0时,该任期值为0。
如果Leader的最大Log索引大于等于当前Peer的NextIndex,则需要将NextIndex以及之后索引的日志均发送给Peer,让Peer快速复制日志。
有些Raft实现会逐个将日志发送给Peer,本质上是相同的,但是会增加RPC连接的数量,不过需要注意TestCount3B测试要求RPC数量不能超过(Server数+4)*3,因此逐个发送日志将有很大概率致使RPC数量超过阈值。
补充sendEntry2Server
在sendEntryToServer函数有一点非常重要,即确定CommitIndex。论文中指出
If there exists an N such that N > commitIndex, a majority of matchIndex[i] ≥ N, and log[N].term == currentTerm: set commitIndex = N (§5.3, §5.4).
翻译:如果存在一个N,使得N>commitIndex,则大多数matchIndex[i]≥N,并且log[N].term==currentTerm:设置commitIndex=N(§5.3,§5.4)。
这意味着Leader每次收到Follower的AppendEntriesReply,应该进行遍历,找出某个值N,使得某个matchIndex值为N的Server数量大于半数。
再次强调实现Raft时应该注意并发问题,如果简单粗暴地认为reply.Success为true即得到一个Server确认,则为会造成逻辑错误。
extIndex与matchIndex的更新存在旧值问题,为了保证幂等性,因此代码应该如此编写:
//更新peer的nextIdx和matchIdx
newNext := args.PrevLogIndex + len(args.Entries) + 1
newMatch := args.PrevLogIndex + len(args.Entries)
//计算当前commitIdx,保证幂等性
rf.nextIndex[server] = max(newNext, rf.nextIndex[server])
rf.matchIndex[server] = max(newMatch, rf.matchIndex[server])
如果reply.Success为false,也应该先判断Follower任期与Leader任期是否一致,以及是否仍然为Leader,为什么?考虑以下情况:
- 如果S1在T1阶段发送了一个AppendEntries给S2,但该AppendEntries消息在网络中迷失;
- 之后S3成为了Leader并变更任期为T2,而S1和S2均成为Follower,任期也变更为T2;
- 此时,S1在T1时刻的迷失消息传递至S2,S2检查消息的任期为T1后拒绝该消息;
- S1收到拒绝信息后,逻辑中将降低NextIndex,然后再次发送给S2,此时消息是T2。
显然,S1不应该再处理该消息了。综合以上,sendEntry2Server完整的代码如下:
func (rf *Raft) sendEntry2Server(server int, args AppendEntriesArgs) {
var reply AppendEntriesReply
if !rf.appendEntries(server, &args, &reply) {
return
}
rf.mu.Lock()
defer rf.mu.Unlock()
if reply.Term > rf.currentTerm {
if rf.state == StateLeader {
DebugPrintf(dInfo, rf.me, "Term:%d > CurrentTerm%d,降级为Follower", reply.Term, rf.currentTerm)
rf.state = StateFollower
}
rf.currentTerm = reply.Term
rf.resetElectionTime()
return
}
if rf.state != StateLeader {
DebugPrintf(dWarn, rf.me, "非Leader,拒绝响应 S%d:%d", server, reply.Term)
return
}
if reply.Term < rf.currentTerm {
DebugPrintf(dWarn, rf.me, "响应的任期号%d更小,拒绝接受", reply.Term, rf.currentTerm)
return
}
if reply.Success {
DebugPrintf(dLeader, rf.me, "S%d成功AppendEntry", server)
//更新peer的nextIdx和matchIdx
newNext := args.PrevLogIndex + len(args.Entries) + 1
newMatch := args.PrevLogIndex + len(args.Entries)
//计算当前commitIdx,需要保证幂等性
rf.nextIndex[server] = max(newNext, rf.nextIndex[server])
rf.matchIndex[server] = max(newMatch, rf.matchIndex[server])
DebugPrintf(dClient, rf.me, "S%d的NextIdx修改为%d,MatchIdx修改为%d", server, rf.nextIndex[server], rf.matchIndex[server])
//寻找commitIdx
DebugPrintf(dLog2, rf.me, "LastLogIndex=%d,commitIndex=%d", rf.LastLogIndex(), rf.commitIndex)
for n := rf.LastLogIndex(); n > rf.commitIndex && rf.GetLog(n).Term == rf.currentTerm; n-- {
cnt := 1
for peer, matchIdx := range rf.matchIndex {
if peer == rf.me {
continue
}
// 如果匹配的索引大于n
if matchIdx >= n {
cnt++
}
}
if cnt > rf.halfPeerNum() {
// n是数组下标,n+1为索引
rf.commitIndex = n
DebugPrintf(dCommit, rf.me, "获取半数Peer同意,更新CommitIdx为%d", n)
break
}
}
} else {
DebugPrintf(dLeader, rf.me, "S%d拒绝AppendEntry", server)
// 减少nextIdx,然后重试
if rf.nextIndex[server] > 1 {
rf.nextIndex[server]--
}
nextIdx := rf.nextIndex[server]
var (
prevLogIndex = nextIdx - 1
prevLogTerm = 0
)
if prevLogIndex != 0 {
prevLogTerm = rf.GetLog(prevLogIndex).Term
}
entries := rf.GetLogSlice(nextIdx, rf.LastLogIndex()+1)
DebugPrintf(dLog2, rf.me, "减少S%d nextId,nextId:%d", server, rf.nextIndex[server])
newArg := AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
PrevLogIndex: prevLogIndex,
PrevLogTerm: prevLogTerm,
Entries: entries,
LeaderCommit: rf.commitIndex,
}
go rf.sendEntry2Server(server, newArg)
}
}
以上代码中的halfPeerNum实现如下,顾名思义,计算Server数量的半数。
func (rf *Raft) halfPeerNum() int {
return len(rf.peers) >> 1
}
补充RPC函数
RequestVote
RequestVote函数需要判断Log,以决定是否投票给该候选者。接受投票的条件为:
- 当前Server的Log为初始情况。
- 候选者的日志任期必须“领先”当前Server。
那什么是更领先?Raft通过比较两份日志中最后一条日志的索引值和任期号定义谁的日志比较领先。
- 如果两份日志最后条目的任期号不同,那么任期号大的日志更领先。
- 如果两份日志最后的条目任期号相同,那么日志比较长(索引值更大)的那个就更领先。
但要注意,选举期间如果两个候选者S1、S2拥有相同的任期,但S2拥有更领先的日志,而S1收到S2的投票请求之后,仍然会投拒绝票,如下图所示。这是因为S1已经将票数投给了自己,因此并不会检查日志情况而直接拒绝选举S2。
// example RequestVote RPC handler.
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
// Your code here (3A, 3B).
rf.mu.Lock()
defer rf.mu.Unlock()
DebugPrintf(dVote, rf.me, "收到候选人S%d选举请求", args.CandidateId)
if args.Term < rf.currentTerm {
DebugPrintf(dVote, rf.me, "拒绝候选者S%d,任期小于自身", args.CandidateId)
reply.VoteGranted = false
reply.Term = rf.currentTerm
return
}
if args.Term > rf.currentTerm {
rf.state = StateFollower
rf.currentTerm = args.Term
rf.votedFor = -1
}
if rf.votedFor == -1 || rf.votedFor == args.CandidateId {
//如果Server存在日志并且最后的日志任期大于候选者,则拒绝。
//如果Server并不是最后日志任期与候选者相等且日志索引小于等于候选者,则拒绝
if rf.LastLogIndex() != 0 && rf.LastLogTerm() >= args.LastLogTerm &&
!(rf.LastLogTerm() == args.LastLogTerm && rf.LastLogIndex() <= args.LastLogIndex) {
reply.VoteGranted = false
reply.Term = rf.currentTerm
DebugPrintf(dVote, rf.me, "候选者S%d日志更旧,拒绝选举", args.CandidateId)
return
}
reply.VoteGranted = true
reply.Term = rf.currentTerm
rf.votedFor = args.CandidateId
DebugPrintf(dVote, rf.me, "选举候选人 S%d", args.CandidateId)
// 重置选举时间
rf.resetElectionTime()
} else {
reply.VoteGranted = false
reply.Term = rf.currentTerm
DebugPrintf(dVote, rf.me, "已选择S%d 拒绝候选人S%d", rf.votedFor, args.CandidateId)
}
}
但在实践中我发现上图所示情况下,若Leader后续没有收到新的日志,则S1和S2始终无法提交任期为2的消息。在Lab3B中,类似的情况会导致的测试TestBasicAgree3B失败。借助上图5个Server的情况,我们分析一下为什么TestBasicAgree3B会失败。
TestBasicAgree3B使用3个Server进行测试。
- 假设存在3个Server,分别是S1、S2和S3,S1在当选Leader时为T1。
- 某时刻,S1收到日志并将其发送给S2和S3。S2和S3收到日志L1并响应,S1收到超过半数的响应,S1将CommitIdx+1,并发送心跳给S2和S3,但心跳消息丢失。
- 此时S2触发选举,任期变为T2,并以候选人身份发送投票消息给S1和S3,S1和S3投票并作为追随者。
- 这个时候只有S1提交了日志L1,而S2和S3均未提交L1,并且在未收到新的Log之前,S2不会更改Commit,至此永远只有一个Log提交,导致测试失败。
与之类似的情况是S1将L1提交之后就宕机了,S2和S3没有收到S1发送来的CommitIndex。而S2发起竞选,此时S1成功恢复并投票,S3同样投票,S2当选为Leader,接下来的情况与上述情况一致,同样导致测试失败。
根据Raft论文,Leader不会直接提交之前任期的日志,这是为了确保安全性,防止已经被覆盖的日志被错误地提交。
以上情况无法通过测试,但并不意味着L1永远不会被提交,虽然S2不会直接提交T1的日志,但它可以通过提交自己任期(T2)的日志来间接提交之前的日志,S2只要收到了新的日志后便有很大概率使L1提交。
有一种常见的技巧可以解决这种问题,该技巧是“空日志条目”。如果没有新的命令,S2可以发送一个空的日志条目(称为no-op条目)。no-op在原始的Raft论文中并没有直接详细讨论,但Diego Ongaro(Raft的作者)在他的博士论文中更详细地讨论了这个概念,它是解决这个问题的有效方法。
Diego Ongaro 在他的博士论文 “Consensus: Bridging Theory and Practice” 中确实更详细地讨论了no-op,原文如下:
“One simple approach is for every leader to commit a blank no-op entry into the log at the start of its term. As soon as this no-op entry is committed, all prior entries in the leader’s log are committed indirectly. This approach has the simplest reasoning, but it adds an extra round trip to all leader changes before a new leader can propose new client requests.”
“一个简单的方法是让每个领导者在其任期开始时提交一个空白的无操作(no-op)条目到日志中。一旦这个无操作条目被提交,领导者日志中的所有先前条目就会被间接提交。这种方法的推理最为简单,但它在新领导者可以提出新的客户端请求之前,为所有领导者变更增加了一个额外的往返过程。”
Ongaro 进一步解释:
“Another way to accomplish this is for the leader to treat the election as an implicit no-op entry, which is committed once the leader learns that a majority of the cluster has voted for it. This approach allows the leader to propose client requests without delay.”
“实现这一目标的另一种方式是让领导者将选举视为一个隐式的无操作条目,一旦领导者得知集群中的多数已经投票支持它,这个条目就被视为已提交。这种方法允许领导者无延迟地提出客户端请求。”
从上面可以得知,Ongaro提出了两种实现方法:
- 显式添加一个no-op条目
- 将选举本身视为一个隐式的no-op条目
这两种方法都能解决新领导者需要提交先前任期日志的问题,但第二种方法可能在效率上略胜一筹,因为它避免了额外的往返通信。本次实验我们不实现no-op条目。
AppendEntries
AppendEntries需要增加同步日志的逻辑,具体含义在注释中说明。
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
DebugPrintf(dClient, rf.me, "收到 S%d AppendEntries", args.LeaderId)
rf.mu.Lock()
defer rf.mu.Unlock()
// 如果收到的任期小于自身,则拒绝Leader
if args.Term < rf.currentTerm {
DebugPrintf(dClient, rf.me, "收到的任期号Term%d小于自身任期号Term%d", args.Term, rf.currentTerm)
DebugPrintf(dTerm, rf.me, "当前任期号:%d", rf.currentTerm)
reply.Success = false
reply.Term = rf.currentTerm
return
}
if rf.state == StateCandidate && rf.currentTerm == args.Term {
rf.state = StateFollower
DebugPrintf(dInfo, rf.me, "由候选者降级为追随者")
}
// 收到的任期大于自身,则追随该Leader
if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
// 如果是Leader或候选人,则降级为Follower
if rf.state == StateLeader || rf.state == StateCandidate {
rf.state = StateFollower
DebugPrintf(dClient, rf.me, "收到的新的任期号Term%d,降级为Follower", rf.currentTerm)
}
}
// 检查Leader的日志是否与追随者相同
if args.PrevLogIndex > 0 && args.PrevLogIndex > rf.LastLogIndex() {
reply.Success = false
reply.Term = rf.currentTerm
DebugPrintf(dInfo, rf.me, "日志Index不一致,收到PrevLogIndex:%d,rf.LastLogIndex=%d", args.PrevLogIndex, rf.LastLogIndex())
return
}
// 如果日志在PrevLogIndex中不包含Term与PrevLogTerm匹配的Entry,则回复false
if rf.LastLogIndex() > 0 && args.PrevLogIndex > 0 && args.PrevLogTerm != rf.GetLog(args.PrevLogIndex).Term {
reply.Success = false
reply.Term = rf.currentTerm
DebugPrintf(dInfo, rf.me, "日志Term不一致,收到的PrevLogTerm: %d,MyPrevLogTerm: %d", args.PrevLogTerm, rf.GetLog(args.PrevLogIndex).Term)
return
}
for i, entry := range args.Entries {
// 第一个判断条件防止并发过程中有旧的数据被重新收到
// 第二个判断条件是截断未提交的过期数据
if rf.LastLogIndex() < args.PrevLogIndex+i+1 || rf.GetLog(args.PrevLogIndex+i+1).Term != entry.Term {
rf.log = append(rf.GetLogSlice(1, args.PrevLogIndex+i+1), args.Entries[i:]...)
break
}
}
DebugPrintf(dInfo, rf.me, "Exist Entries: %v", rf.log)
// 5. 如果leaderCommit > commitIndex,则commitIndex设置为min(leaderCommit,最新Entry的索引)
if args.LeaderCommit > rf.commitIndex {
DebugPrintf(dInfo, rf.me, "收到Leader CommitIdx为%d", args.LeaderCommit)
// 不能超过Leader的Commit。如果Server的Log比较滞后,args.PrevLogIndex+len(args.Entries)能快速更新commitIdx
rf.commitIndex = min(args.LeaderCommit, args.PrevLogIndex+len(args.Entries))
DebugPrintf(dCommit, rf.me, "更新CommitIdx为%d", rf.commitIndex)
}
reply.Term = rf.currentTerm
reply.Success = true
rf.resetElectionTime()
}
运行结果
Test (3B): basic agreement ...
... Passed -- 1.5 3 16 4140 3
Test (3B): RPC byte count ...
... Passed -- 3.2 3 48 113016 11
Test (3B): test progressive failure of followers ...
... Passed -- 5.5 3 64 13567 3
Test (3B): test failure of leaders ...
... Passed -- 5.9 3 98 21401 3
Test (3B): agreement after follower reconnects ...
... Passed -- 6.7 3 77 19701 8
Test (3B): no agreement if too many followers disconnect ...
... Passed -- 4.0 5 112 24030 3
Test (3B): concurrent Start()s ...
... Passed -- 1.3 3 22 5971 6
Test (3B): rejoin of partitioned leader ...
... Passed -- 7.4 3 101 24185 4
Test (3B): leader backs up quickly over incorrect follower logs ...
... Passed -- 32.4 5 2115 1569372 103
Test (3B): RPC counts aren't too high ...
... Passed -- 2.8 3 44 13840 12
PASS
ok 6.5840/raft 70.757s
Lab-3C - 持久化
任务要求
通过添加代码保存和恢复持久状态,完成 raft.go 中的 persist() 和 readPersist() 功能。您需要将状态序列化为字节数组,以便将其传递给 Persister 。使用 labgob 编码器;
请参见 persist() 和 readPersist() 中的注释。 labgob 类似于 Go 的 gob 编码器,但如果尝试对具有小写字段名称的结构进行编码,则会打印错误消息。
在进行3D实验之前,应该将 nil 作为第二个参数传递给 persister.Save() 。在您的实现更改持久状态的点插入 persist() 调用。完成此操作后,如果您的其余实现正确,则应通过所有 3C 测试。
您可能需要优化一次备份多个Item的nextIndex。看看从第7页底部和第8页顶部开始的扩展Raft论文(用灰色线标记) 。
这篇论文对细节含糊其辞;你需要填补空白。一种可能是,拒绝消息包括:
XTerm: term in the conflicting entry (if any)
XIndex: index of first entry with that term (if any)
XLen: log length
那么,Leader的逻辑可以是这样的:
Case 1: leader doesn't have XTerm:
nextIndex = XIndex
Case 2: leader has XTerm:
nextIndex = leader's last entry for XTerm
Case 3: follower's log is too short:
nextIndex = XLen
实验准备
实际上,Lab3C可以分为两部分,一部分是实现持久化,另一部分是优化nextIndex。

根据论文图2,所有Peer应该持久化currentTerm,votedFor,log[]。因此,这些参数发生变化的地方都需要执行一次持久化操作。
Lab3C是整个Lab3中难度最低的实验,代码骨架中已经帮我们调用了读取持久化的代码,我们只需要实现Persist方法和readPersist方法即可。
持久化实现
persist方法
任务要求中已经指出我们应该使用labgob编码器,且persist方法已经给出了示例代码。
func (rf *Raft) persist() {
// Your code here (3C).
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
// currentTerm
err := e.Encode(rf.currentTerm)
if err != nil {
DebugPrintf(dError, rf.me, "序列化 rf.currentTerm 失败。err: %s", err.Error())
}
// votedFor
err = e.Encode(rf.votedFor)
if err != nil {
DebugPrintf(dError, rf.me, "序列化 rf.votedFor 失败。err: %s", err.Error())
}
// log[]
err = e.Encode(rf.log)
if err != nil {
DebugPrintf(dError, rf.me, "序列化 rf.log 失败。err: %s", err.Error())
}
raftState := w.Bytes()
rf.persister.Save(raftState, nil)
DebugPrintf(dPersist, rf.me, "持久化执行成功")
}
readPersist方法
同理,readPersist也给出了示例代码,按照示例代码能快速实现。
func (rf *Raft) readPersist(data []byte) {
if data == nil || len(data) < 1 { // bootstrap without any state?
return
}
// Your code here (3C).
r := bytes.NewBuffer(data)
d := labgob.NewDecoder(r)
rf.mu.Lock()
defer rf.mu.Unlock()
err := d.Decode(&rf.currentTerm)
if err != nil {
DebugPrintf(dError, rf.me, "反序列化 rf.currentTerm 失败。err: %s", err.Error())
}
err = d.Decode(&rf.votedFor)
if err != nil {
DebugPrintf(dError, rf.me, "反序列化 rf.votedFor 失败。err: %s", err.Error())
}
err = d.Decode(&rf.log)
if err != nil {
DebugPrintf(dError, rf.me, "反序列化 rf.log 失败。err: %s", err.Error())
}
}
实现以上函数后,只需要在currentTerm,votedFor,log[]参数发生变化的地方都需要执行一次持久化操作即可。
可以借助IDE的查找功能来找到currentTerm,votedFor,log[]发生改变的地方,此处不再赘述。
nextIndex优化
如果不进行nextIndex优化,可能会导致测试用例超时。我们需要使NextId能尽量一次就到达冲突点。
论文原文描述如下:
If desired, the protocol can be optimized to reduce the number of rejected AppendEntries RPCs. For example, when rejecting an AppendEntries request, the follower can include the term of the conflicting entry and the first index it stores for that term. With this information, the leader can decrement nextIndex to bypass all of the conflicting entries in that term; one AppendEntries RPC will be required for each term with conflicting entries, rather than one RPC per entry. In practice, we doubt this optimization is necessary, since failures happen infrequently and it is unlikely that there will be many inconsistent entries.
如果需要,可以通过优化协议来减少被拒绝的AppendEntries RPC的数量。例如,当Follower拒绝一个AppendEntries请求时,它可以向领导者提供冲突条目的Term以及存储该任期的第一个索引。有了这些信息,Leader就可以通过减小nextIndex来跳过该冲突任期中的所有冲突条目。这样,每个冲突的任期只需要一个AppendEntries RPC,而不是每个冲突条目都需要一个RPC,从而减少同步日志的成本。但在实践中,我们怀疑这种优化并不是很必要,因为不一致的条目非常少见。
论文并没有详细说明实现方法,但3C任务给了我们提示。一种可能的实现是让拒绝消息体中包括
| 字段名 | 说明 |
|---|---|
| XTerm | 如果存在的话,表示发生冲突位置日志的Term任期 |
| XIndex | 如果存在的话,表示该任期的第一个日志索引 |
| XLen | 已经复制的日志长度 |
而Leader接收到消息体后,可以根据不同的情况处理:
| 情况 | 说明 |
|---|---|
| Leader不存在XTerm | nextIndex = XIndex |
| Leader存在XTerm | nextIndex = Leader日志中属于XTerm任期的最大日志索引 |
| Follower的日志过短 | nextIndex = XLen |
修改AppendEntries
首先,按照上述方法,给AppendEntriesReply新增字段。
type AppendEntriesReply struct {
Term int
Success bool
//Extend
XTerm int
XIndex int
XLen int
}
为了方便处理,我们可以实现一个方法来计算某个任期的最大索引与最小索引。当任期不存在时,索引返回0。
func (rf *Raft) TermRange(term int) (minIdx, maxIdx int) {
minIdx, maxIdx = math.MaxInt, -1
for i := 0; i < len(rf.log); i++ {
if rf.log[i].Term == term {
minIdx = min(minIdx, i)
maxIdx = max(maxIdx, i)
}
}
if maxIdx == -1 {
minIdx = -1
}
// 大小值均+1,表示索引(索引从1开始)
return minIdx + 1, maxIdx + 1
}
以上工作完成后,我们需要修改AppendEntries方法,为拓展字段赋值。
// AppendEntries RPC 发送心跳或者日志提交
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
DebugPrintf(dClient, rf.me, "收到 S%d AppendEntries", args.LeaderId)
rf.mu.Lock()
defer rf.mu.Unlock()
// 如果收到的任期小于自身,则拒绝Leader
if args.Term < rf.currentTerm {
DebugPrintf(dClient, rf.me, "收到的任期号Term%d小于自身任期号Term%d", args.Term, rf.currentTerm)
DebugPrintf(dTerm, rf.me, "当前任期号:%d", rf.currentTerm)
reply.Success = false
reply.Term = rf.currentTerm
// Extend
reply.XTerm = -1 // 不存在
reply.XIndex = 0 // 不存在
reply.XLen = rf.LastLogIndex()
return
}
if rf.state == StateCandidate && rf.currentTerm == args.Term {
rf.state = StateFollower
DebugPrintf(dInfo, rf.me, "由候选者降级为追随者")
}
// 收到的任期大于自身,则追随该Leader
if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
// 如果是Leader或候选人,则降级为Follower
if rf.state == StateLeader || rf.state == StateCandidate {
rf.state = StateFollower
DebugPrintf(dClient, rf.me, "收到的新的任期号Term%d,降级为Follower", rf.currentTerm)
}
}
// 检查Leader的日志是否与追随者相同
if args.PrevLogIndex > 0 && args.PrevLogIndex > rf.LastLogIndex() {
reply.Success = false
reply.Term = rf.currentTerm
//Extend: Follower的Log过短,并非发生冲突
reply.XLen = rf.LastLogIndex()
reply.XTerm = -1
reply.XIndex = 0
DebugPrintf(dInfo, rf.me, "日志Index不一致,收到PrevLogIndex:%d,rf.LastLogIndex=%d", args.PrevLogIndex, rf.LastLogIndex())
return
}
// 如果日志在PrevLogIndex中不包含Term与PrevLogTerm匹配的Entry,则回复false
if rf.LastLogIndex() > 0 && args.PrevLogIndex > 0 && args.PrevLogTerm != rf.GetLog(args.PrevLogIndex).Term {
reply.Success = false
reply.Term = rf.currentTerm
// Extend: 冲突信息
reply.XTerm = rf.GetLog(args.PrevLogIndex).Term
reply.XLen = rf.LastLogIndex()
reply.XIndex, _ = rf.TermRange(reply.XTerm)
DebugPrintf(dInfo, rf.me, "日志Term不一致,收到的PrevLogTerm: %d,MyPrevLogTerm: %d", args.PrevLogTerm, rf.GetLog(args.PrevLogIndex).Term)
return
}
for i, entry := range args.Entries {
// 第一个判断条件防止并发过程中有旧的数据被重新收到
// 第二个判断条件是截断未提交的过期数据
if rf.LastLogIndex() < args.PrevLogIndex+i+1 || rf.GetLog(args.PrevLogIndex+i+1).Term != entry.Term {
rf.log = append(rf.GetLogSlice(1, args.PrevLogIndex+i+1), args.Entries[i:]...)
break
}
}
DebugPrintf(dInfo, rf.me, "Exist Entries: %v", rf.log)
// 5. 如果leaderCommit > commitIndex,则commitIndex设置为min(leaderCommit,最新Entry的索引)
if args.LeaderCommit > rf.commitIndex {
DebugPrintf(dInfo, rf.me, "收到Leader CommitIdx为%d", args.LeaderCommit)
// 不能超过Leader的Commit。如果Peer的Log比较滞后,args.PrevLogIndex+len(args.Entries)能快速更新commitIdx
rf.commitIndex = min(args.LeaderCommit, args.PrevLogIndex+len(args.Entries))
DebugPrintf(dCommit, rf.me, "更新CommitIdx为%d", rf.commitIndex)
}
reply.Term = rf.currentTerm
reply.Success = true
rf.resetElectionTime()
}
修改sendEntry2Server
func (rf *Raft) sendEntry2Server(server int, args AppendEntriesArgs) {
var reply AppendEntriesReply
if !rf.appendEntries(server, &args, &reply) {
return
}
rf.mu.Lock()
defer rf.mu.Unlock()
if reply.Term > rf.currentTerm {
if rf.state == StateLeader {
DebugPrintf(dInfo, rf.me, "Term:%d > CurrentTerm%d,降级为Follower", reply.Term, rf.currentTerm)
rf.state = StateFollower
}
rf.currentTerm = reply.Term
rf.resetElectionTime()
return
}
if rf.state != StateLeader {
DebugPrintf(dWarn, rf.me, "非Leader,拒绝响应 S%d:%d", server, reply.Term)
return
}
if reply.Term < rf.currentTerm {
DebugPrintf(dWarn, rf.me, "响应的任期号%d更小,拒绝接受", reply.Term, rf.currentTerm)
return
}
if reply.Success {
DebugPrintf(dLeader, rf.me, "S%d成功AppendEntry", server)
//更新peer的nextIdx和matchIdx
newNext := args.PrevLogIndex + len(args.Entries) + 1
newMatch := args.PrevLogIndex + len(args.Entries)
//计算当前commitIdx,需要保证幂等性
rf.nextIndex[server] = max(newNext, rf.nextIndex[server])
rf.matchIndex[server] = max(newMatch, rf.matchIndex[server])
DebugPrintf(dClient, rf.me, "S%d的NextIdx修改为%d,MatchIdx修改为%d", server, rf.nextIndex[server], rf.matchIndex[server])
//寻找commitIdx
DebugPrintf(dLog2, rf.me, "LastLogIndex=%d,commitIndex=%d", rf.LastLogIndex(), rf.commitIndex)
for n := rf.LastLogIndex(); n > rf.commitIndex && rf.GetLog(n).Term == rf.currentTerm; n-- {
cnt := 1
for peer, matchIdx := range rf.matchIndex {
if peer == rf.me {
continue
}
// 如果匹配的索引大于n
if matchIdx >= n {
cnt++
}
}
if cnt > rf.halfPeerNum() {
// n是数组下标,n+1为索引
rf.commitIndex = n
DebugPrintf(dCommit, rf.me, "获取半数Peer同意,更新CommitIdx为%d", n)
break
}
}
} else {
DebugPrintf(dLeader, rf.me, "S%d拒绝AppendEntry", server)
// 减少nextIdx,然后重试
//if rf.nextIndex[server] > 1 {
// rf.nextIndex[server]--
//}
// extend
if reply.XTerm == -1 {
rf.nextIndex[server] = reply.XLen + 1
DebugPrintf(dLog, rf.me, "S%d XTerm == -1,nextIdx -> reply.XLen + 1", server)
} else {
_, maxIdx := rf.TermRange(reply.XTerm)
if maxIdx == 0 {
rf.nextIndex[server] = reply.XIndex
DebugPrintf(dLog, rf.me, "Leader no XTerm%d ,S%d nextIdx -> %d", reply.XTerm, server, reply.XIndex)
} else {
rf.nextIndex[server] = maxIdx
DebugPrintf(dLog, rf.me, "Leader has XTerm%d ,S%d nextIdx -> %d", reply.XTerm, server, maxIdx)
}
}
if len(rf.log) < rf.nextIndex[server] {
return
}
nextIdx := rf.nextIndex[server]
var (
prevLogIndex = nextIdx - 1
prevLogTerm = 0
)
if prevLogIndex != 0 {
prevLogTerm = rf.GetLog(prevLogIndex).Term
}
entries := rf.GetLogSlice(nextIdx, rf.LastLogIndex()+1)
DebugPrintf(dLog2, rf.me, "减少S%d nextId,nextId:%d", server, rf.nextIndex[server])
newArg := AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
PrevLogIndex: prevLogIndex,
PrevLogTerm: prevLogTerm,
Entries: entries,
LeaderCommit: rf.commitIndex,
}
go rf.sendEntry2Server(server, newArg)
}
}
注意,上面的代码新增了
if len(rf.log) < rf.nextIndex[server] {
return
}
如果不添加以上代码将会发生错误。考虑这种情况:当S1在T1任期发送了一个AppendEntries请求,但S2并没有收到,之后S1再次当选Leader,向S2发送AppendEntries,S2同步Log之后,收到了T1时的AppendEntries请求,此时会拒绝而响应false,S1会修改nextIndex为Len(S2.Log)+1,如果S1的Log与S2相同,那么S1下一次发送给S2的Entries将会发生数组越界异常。
运行结果
Test (3C): basic persistence ...
labgob warning: Decoding into a non-default variable/field int may not work
... Passed -- 5.6 3 54 13266 6
Test (3C): more persistence ...
... Passed -- 20.8 5 610 128556 16
Test (3C): partitioned leader and one follower crash, leader restarts ...
... Passed -- 2.7 3 31 7528 4
Test (3C): Figure 8 ...
... Passed -- 31.9 5 556 118623 35
Test (3C): unreliable agreement ...
... Passed -- 2.1 5 1000 315603 246
Test (3C): Figure 8 (unreliable) ...
... Passed -- 33.6 5 6382 7293379 244
Test (3C): churn ...
... Passed -- 16.4 5 4243 7685050 1036
Test (3C): unreliable churn ...
... Passed -- 16.6 5 3005 4153099 723
PASS
ok 6.5840/raft 129.596s
Lab-3D-快照Snapshot
目前,重启服务器会按顺序重放完整的 Raft 日志以恢复其状态。然而,长时间运行的服务无法永久记住完整的 Raft 日志,这是不切实际的。
相反,您将修改 Raft 以与持久存储其状态的服务合作,这些服务会不时地存储其状态的“快照”,此时 Raft 会丢弃在快照之前的日志条目。结果是更少的持久数据和更快的重启。
但是,现在可能会出现追随者落后太远,以至于领导者已经丢弃了它需要追赶的日志条目;然后领导者必须发送一个快照以及从快照时间开始的日志。
任务要求
在实验室 3D 中,Tester定期调用Snapshot()。在Lab-4中,您将编写一个k-v服务器,调用Snapshot();快照将包含完整的键/值对表。服务层在每个对等节点上调用 Snapshot() (而不仅仅是在领导者上)。
index 参数表示快照中反映的最高日志条目。Raft 应该在该点之前丢弃其日志条目。您需要修改 Raft 代码,仅在存储日志尾部时运行。
您需要实现论文中讨论的 InstallSnapshot RPC,以允许 Raft 领导者告诉滞后的 Raft 同行使用快照替换其状态。您可能需要仔细考虑 InstallSnapshot 如何与图 2 中的状态和规则交互。
当追随者的 Raft 代码接收到 InstallSnapshot RPC 时,它可以使用 applyCh 将快照发送到 ApplyMsg 中的服务。 ApplyMsg 结构定义已经包含了您需要的字段(Tester期望的字段)。请注意,这些快照只会推进服务的状态,而不会使其后退。
如果服务器崩溃,必须从持久化数据重新启动。您的 Raft 应该持久化 Raft 状态和相应的快照。使用第二个参数 persister.Save() 保存快照。如果没有快照,请将 nil 作为第二个参数传递。
当服务器重新启动时,应用层会读取持久化的快照并恢复其保存的状态。
提示:
- 以单个 InstallSnapshot RPC 发送完整的快照。不要实现
Figure 13的 offset 机制来拆分快照。

实现——准备步骤
任务要求中,已经明确告诉我们不要按照论文图13的Chunk-Offset机制来拆分快照。所以,我们定义的PRC请求结构体与论文描述会有略微差异。
Raft结构体
Raft结构体新增Snapshot相关字段。
type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
// Your data here (3A, 3B, 3C).
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
state State
heartBeatTime time.Time
electionTime time.Time
// 以下字段论文原文
currentTerm int // 当前任期
votedFor int // 投票给的候选者ID
log []LogEntry // 日志
commitIndex int // 已经提交的最高日志条目索引
lastApplied int // 已经应用到状态机的最高日志条目索引
nextIndex []int // 对每个服务器,要发送的下一跳日志条目的索引
matchIndex []int // 对每个服务器,已知被复制的最高日志条目的索引
// SnapShot
applyCh chan ApplyMsg
LastIncludedIndex int
LastIncludedTerm int
SnapShot []byte
}
结构体中新增了applyCh,用于提交快照,为了方便处理,我们实现commitSnap方法。
func (rf *Raft) commitSnap(msg ApplyMsg) {
rf.applyCh <- msg
DebugPrintf(dSnap, rf.me, "commit Snap idx:%d-Term:%d", msg.SnapshotIndex, msg.SnapshotTerm)
}
再实现readPersistSnapshot方法。
func (rf *Raft) readPersistSnapshot(data []byte) {
rf.mu.Lock()
defer rf.mu.Unlock()
rf.SnapShot = data
}
persist&readPersist方法
正如任务要求所说,如果服务器崩溃,我们必须从持久化数据重新启动。
我们应该持久化 Raft 状态和相应的**Snapshot,**首先,我们修改persist()和readPersist()方法。
// 将 Raft 的持久状态保存到稳定存储中,
// 这样在发生崩溃并重新启动后可以检索到这些状态。
// 请参见论文中的图 2,了解哪些内容应该是持久化的。
// 在实现快照之前,应该将 nil 作为第二个参数传递给 persister.Save()。
// 在实现快照之后,传递当前的快照(如果还没有快照,传递 nil)。
func (rf *Raft) persist() {
// Your code here (3C).
w := new(bytes.Buffer)
// ...省略
// log[]
err = e.Encode(rf.log)
if err != nil {
DebugPrintf(dError, rf.me, "序列化 rf.log 失败。err: %s", err.Error())
}
// snapshot
err = e.Encode(rf.LastIncludedIndex)
if err != nil {
DebugPrintf(dError, rf.me, "序列化 rf.LastIncludedIndex 失败。err: %s", err.Error())
}
err = e.Encode(rf.LastIncludedTerm)
if err != nil {
DebugPrintf(dError, rf.me, "序列化 rf.LastIncludedTerm 失败。err: %s", err.Error())
}
raftState := w.Bytes()
if len(rf.SnapShot) != 0 {
rf.persister.Save(raftState, rf.SnapShot)
} else {
rf.persister.Save(raftState, nil)
}
DebugPrintf(dPersist, rf.me, "持久化执行成功")
}
func (rf *Raft) readPersist(data []byte) {
if data == nil || len(data) < 1 { // bootstrap without any state?
return
}
// Your code here (3C).
r := bytes.NewBuffer(data)
// ...省略
err = d.Decode(&rf.log)
if err != nil {
DebugPrintf(dError, rf.me, "反序列化 rf.log 失败。err: %s", err.Error())
}
// snapshot
err = d.Decode(&rf.LastIncludedIndex)
if err != nil {
DebugPrintf(dError, rf.me, "反序列化 rf.LastIncludedIndex 失败。err: %s", err.Error())
}
err = d.Decode(&rf.LastIncludedTerm)
if err != nil {
DebugPrintf(dError, rf.me, "反序列化 rf.LastIncludedTerm 失败。err: %s", err.Error())
}
DebugPrintf(dPersist, rf.me, "读取持久数据成功")
}
Make方法
初始化Server的函数增加读取Snapshot持久化数据的代码。
func Make(peers []*labrpc.ClientEnd, me int,
// ...省略
go rf.commitMsg(applyCh) // 新增
// initialize from state persisted before a crash
rf.readPersist(persister.ReadRaftState())
rf.readPersistSnapshot(persister.ReadSnapshot()) // 新增
// start ticker goroutine to start elections
go rf.ticker()
return rf
}
Snapshot方法
仓库代码已经给了Snapshot的骨架代码,我们需要实现它。
func (rf *Raft) Snapshot(index int, snapshot []byte) {
// Your code here (3D).
rf.mu.Lock()
defer rf.mu.Unlock()
if index > len(rf.log) {
DebugPrintf(dError, rf.me, "SnapShot Idx > LogLastIdx")
return
}
if index < rf.LastIncludedIndex {
DebugPrintf(dWarn, rf.me, "SnapShotIdx < LastIncludedIdx")
return
}
DebugPrintf(dSnap, rf.me, "Get SnapShot cmd, Idx : %d", index)
DebugPrintf(dSnap, rf.me, "old Log : %v", rf.log)
CutLog := rf.GetLog(index)
rf.log = rf.GetLogSlice(index+1, rf.LastLogIndex()+1)
DebugPrintf(dInfo, rf.me, "new Log : %v", rf.log)
rf.LastIncludedIndex = index
rf.LastIncludedTerm = CutLog.Term
DebugPrintf(dSnap, rf.me, "LastIncludedTerm:%d LastIncludedIndex:%d", rf.LastIncludedTerm, rf.LastIncludedIndex)
rf.SnapShot = snapshot
rf.persist()
}
实现——核心步骤
InstallSnapshot RPC
按照论文所述,实现请求和响应结构体。
完成Lab3D并不需要实现offset和done。
type InstallSnapshotArgs struct {
Term int
LeaderId int
LastIncludedIndex int
LastIncludedTerm int
Data []byte
//Offset int
//Done bool
}
type InstallSnapshotReply struct {
Term int
}
InstallSnapshot是接收快照信息的RPC函数。
func (rf *Raft) InstallSnapshot(args *InstallSnapshotArgs, reply *InstallSnapshotReply) {
DebugPrintf(dSnap, rf.me, "Recv S%d InstallSnapShot", args.LeaderId)
rf.mu.Lock()
defer rf.mu.Unlock()
if args.Term < rf.currentTerm {
DebugPrintf(dTerm, rf.me, "Recv Snap Term:%d < CurrentTerm:%d", args.Term, rf.currentTerm)
reply.Term = rf.currentTerm
return
}
if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
rf.votedFor = args.LeaderId
rf.persist()
if rf.state == StateLeader || rf.state == StateCandidate {
rf.state = StateFollower
DebugPrintf(dInfo, rf.me, "降级为Follower")
}
reply.Term = rf.currentTerm
}
rf.resetElectionTime()
if args.LastIncludedIndex <= rf.lastApplied {
reply.Term = rf.currentTerm
DebugPrintf(dInfo, rf.me, "args.LastIncludedIndex:%d < rf.lastApplied:%d", args.LastIncludedIndex, rf.lastApplied)
return
}
// 找到Index
if args.LastIncludedIndex > rf.LastLogIndex() || rf.GetLog(args.LastIncludedIndex).Term != args.LastIncludedTerm {
DebugPrintf(dDrop, rf.me, "没有找到索引%d,丢弃所有日志", args.LastIncludedIndex)
rf.log = []LogEntry{}
} else {
DebugPrintf(dDrop, rf.me, "找到索引%d,丢弃部分日志", args.LastIncludedIndex)
rf.log = rf.GetLogSlice(args.LastIncludedIndex+1, rf.LastLogIndex()+1)
}
// 更改状态
rf.LastIncludedTerm = args.LastIncludedTerm
rf.LastIncludedIndex = args.LastIncludedIndex
rf.lastApplied = max(args.LastIncludedIndex, rf.lastApplied)
rf.commitIndex = max(args.LastIncludedIndex, rf.commitIndex)
rf.SnapShot = args.Data
rf.persist()
rf.commitSnap(ApplyMsg{
SnapshotValid: true,
Snapshot: args.Data,
SnapshotTerm: args.LastIncludedTerm,
SnapshotIndex: args.LastIncludedIndex,
})
}
sendInstallSnapshot
主动调用InstallSnapshot RPC函数。
func (rf *Raft) installSnapshot(server int, args *InstallSnapshotArgs, reply *InstallSnapshotReply) bool {
return rf.peers[server].Call("Raft.InstallSnapshot", args, reply)
}
func (rf *Raft) sendInstallSnapshot(server int) {
DebugPrintf(dSnap, rf.me, "Send SnapShot to S%d", server)
rf.mu.Lock()
args := InstallSnapshotArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
LastIncludedIndex: rf.LastIncludedIndex,
LastIncludedTerm: rf.LastIncludedTerm,
Data: rf.SnapShot,
}
rf.mu.Unlock() // 为什么不用 defer rf.mu.Unlock()?见文章后续说明
var reply InstallSnapshotReply
if ok := rf.installSnapshot(server, &args, &reply); !ok {
DebugPrintf(dError, rf.me, "Send Snapshot RPC to S%d failed", server)
return
}
rf.mu.Lock()
defer rf.mu.Unlock()
if reply.Term < rf.currentTerm {
DebugPrintf(dInfo, rf.me, "sendInstallSnapshot Reply.Term < CurrentTerm")
return
}
if reply.Term > rf.currentTerm {
rf.currentTerm = reply.Term
if rf.state == StateLeader || rf.state == StateCandidate {
rf.state = StateFollower
}
rf.votedFor = -1
rf.resetElectionTime()
rf.persist()
return
}
newMatch := args.LastIncludedIndex
newNext := args.LastIncludedIndex + 1
rf.matchIndex[server] = max(newMatch, rf.matchIndex[server])
rf.nextIndex[server] = max(newNext, rf.nextIndex[server])
}
活锁问题
我在实现过程中,发现两个奇怪的现象:
- 最后的错误日志会显示某个LogA未达成共识,但查询打印日志发现,并未有任何Server收到了LogA。根据单元测试代码,如果Tester发送了某个日志,这个日志在10s后还没有被Server接收,则报错,可见程序的打印日志是不会有记录的,因为一直没有Server接收。
- 最后所有的Server都变为候选人,但没有选出Leader。Server1无法与Server2、Server3通信,一直在更新任期并请求投票,而Server2与Server3能够通信,但是Server2的任期号比Server3更大,Log却比Server3低,Server3永远在追赶Server2的任期号。
上述两种情况的本质原因是代码中发生了活锁。
通过排查日志发现是加锁错误导致的。当Server3到达重新选举时间,因为Server3发送SnapShot给Server1获取的锁一直没有释放,使得Server2又重新发起了选举,造成Server3永远追赶Server2,日志无法达成一致。
正常情况下,Server3不会永远追赶Server2,因为Server3收到新的任期请求时不会重置选举时间,而仅仅是更新任期号。
func (rf *Raft) sendInstallSnapshot(server int) {
DebugPro(dSnap, rf.me, "Send SnapShot to S%d", server)
rf.mu.Lock()
// defer rf.mu.Unlock() //原本是在这里释放锁,当rf.installSnapshot卡住时,锁无法释放
args := InstallSnapshotArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
LastIncludedIndex: rf.LastIncludedIndex,
LastIncludedTerm: rf.LastIncludedTerm,
Data: rf.SnapShot,
}
rf.mu.Unlock() // 创建了请求结构体之后便可释放锁
var reply InstallSnapshotReply
if ok := rf.installSnapshot(server, &args, &reply); !ok {
DebugPro(dError, rf.me, "Send Snapshot RPC to S%d failed", server)
return
}
rf.mu.Lock()
defer rf.mu.Unlock()
//... 省略
}
发送SnapShot判断
当Follower的nextIndex比Leader的LastIncludedIndex小,此时Leader无法将日志发送给该Follower,而是将Snapshot信息传递给它。
我们需要修改broadcastEntries方法。
func (rf *Raft) broadcastEntries() {
DebugPrintf(dLeader, rf.me, "开始广播AppendEntries")
for i := 0; i < len(rf.peers); i++ {
if i == rf.me {
continue
}
var (
prevLogIndex int
prevLogTerm int
entries []LogEntry
)
// 【新增】判断是否为压缩日志
DebugPrintf(dInfo, rf.me, "To S%d nextIndex:%d LastIncludedIndex:%d", i, rf.nextIndex[i], rf.LastIncludedIndex)
if rf.nextIndex[i] <= rf.LastIncludedIndex {
go rf.sendInstallSnapshot(i)
continue
}
prevLogIndex = rf.nextIndex[i] - 1
if rf.nextIndex[i]-1 != 0 {
prevLogTerm = rf.GetLog(prevLogIndex).Term
}
// ...... 省略
}
同理,我们还需要修改sendEntry2Server方法。
func (rf *Raft) sendEntry2Server(server int, args AppendEntriesArgs) {
var reply AppendEntriesReply
if !rf.appendEntries(server, &args, &reply) {
return
}
rf.mu.Lock()
defer rf.mu.Unlock()
if reply.Term > rf.currentTerm {
// ...省略
}
if rf.state != StateLeader {
// ...省略
}
if reply.Term < rf.currentTerm {
// ...省略
}
if reply.Success {
// ...省略
} else {
DebugPrintf(dLeader, rf.me, "S%d拒绝AppendEntry", server)
// 减少nextIdx,然后重试
//if rf.nextIndex[server] > 1 {
// rf.nextIndex[server]--
//}
// extend
if reply.XTerm == -1 {
rf.nextIndex[server] = reply.XLen + 1
DebugPrintf(dLog, rf.me, "S%d XTerm == -1,nextIdx -> reply.XLen + 1", server)
} else {
_, maxIdx := rf.TermRange(reply.XTerm)
if maxIdx == 0 {
rf.nextIndex[server] = reply.XIndex
DebugPrintf(dLog, rf.me, "Leader no XTerm%d ,S%d nextIdx -> %d", reply.XTerm, server, reply.XIndex)
} else {
rf.nextIndex[server] = maxIdx
DebugPrintf(dLog, rf.me, "Leader has XTerm%d ,S%d nextIdx -> %d", reply.XTerm, server, maxIdx)
}
}
if len(rf.log) < rf.nextIndex[server] {
return
}
// 【新增】判断是否需要发送快照
if rf.nextIndex[server] <= rf.LastIncludedIndex {
DebugPrintf(dInfo, rf.me, "nextIndex < LastIncludedIndex,发送快照")
go rf.sendInstallSnapshot(server)
return
}
nextIdx := rf.nextIndex[server]
// ......省略
}
}
修改commitMsg
在提交Msg时,需要将*rf.lastApplied与rf.LastIncludedIndex进行比较,较大的值才是最终的rf*.lastApplied。
且在初始化ApplyMsg数组时,要注意cap值要确保不能为负数,rf.lastApplied有可能大于*rf*.commitIndex,因此最好将cap去掉。
func (rf *Raft) commitMsg(applyCh chan ApplyMsg) {
for !rf.killed() {
msg := make([]ApplyMsg, 0)
rf.mu.Lock()
// 【新增】
rf.lastApplied = max(rf.lastApplied, rf.LastIncludedIndex)
// lastApplied为索引号,从1开始
for rf.lastApplied < rf.commitIndex {
// ...省略
}
// ...省略
}
}
修改Log相关函数
增加Snapshot之后,原本的rf.Log切片并不能表示所有的日志,需要修改Log相关函数,考虑日志因快照被截断的情况。
修改之后的TermRange方法如下,但需要注意返回值无需再+1,因为minIdx和maxIdx已经初始值就为1。
func (rf *Raft) TermRange(term int) (minIdx, maxIdx int) {
if term == 0 {
return 0, 0
}
minIdx, maxIdx = math.MaxInt, -1
for i := rf.LastIncludedIndex + 1; i <= rf.LastLogIndex(); i++ {
if rf.GetLog(i).Term == term {
minIdx = min(minIdx, i)
maxIdx = max(maxIdx, i)
}
}
if maxIdx == -1 {
minIdx = -1
}
return minIdx, maxIdx
}
修改GetLog
func (rf *Raft) GetLog(index int) LogEntry {
idx := index - rf.LastIncludedIndex
if idx < 0 {
log.Panicf("idx:%d < 0", idx)
}
if idx == 0{
return LogEntry{
Term: rf.LastIncludedTerm,
Command: nil,
}
}
if idx > len(rf.log) {
return LogEntry{
Term: 0,
Command: nil,
}
}
return rf.log[idx-1]
}
修改GetLogSlice
func (rf *Raft) GetLogSlice(left, right int) []LogEntry {
if left > right {
panic("left > right")
}
if left < 1 || right > rf.LastLogIndex()+1 {
panic("数组越界")
}
left, right = left-rf.LastIncludedIndex, right-rf.LastIncludedIndex
newLog := make([]LogEntry, right-left)
copy(newLog, rf.log[left-1:right-1])
return newLog
}
修改LastLogIndex
func (rf *Raft) LastLogIndex() int {
idx := len(rf.log) + rf.LastIncludedIndex
return idx
}
修改AppendEntires
Follower接收日志时需要判断SnapShot的状态。任务要求已经说明,服务层会对每个Peer调用 Snapshot() ,而不仅仅是在Leader,这可能会造成一种情况:Follower比Leader更先进行快照。
这种情况导致的结果便是Leader发送的PrevLogIndex比Follower的LastIncludedIndex更小,因此我们添加一条判断语句,如果小于,则返回true,待下一次同步日志恢复一致状态。
此外,SnapShot会改变日志数组的结构,需要修改调用GetLogSlice方法的代码。
// AppendEntries RPC 发送心跳或者日志提交
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
DebugPrintf(dClient, rf.me, "收到 S%d AppendEntries", args.LeaderId)
rf.mu.Lock()
defer rf.mu.Unlock()
// 如果收到的任期小于自身,则拒绝Leader
if args.Term < rf.currentTerm {
DebugPrintf(dClient, rf.me, "收到的任期号Term%d小于自身任期号Term%d", args.Term, rf.currentTerm)
DebugPrintf(dTerm, rf.me, "当前任期号:%d", rf.currentTerm)
reply.Success = false
reply.Term = rf.currentTerm
// Extend
reply.XTerm = -1 // 不存在
reply.XIndex = 0 // 不存在
reply.XLen = rf.LastLogIndex()
return
}
if rf.state == StateCandidate && rf.currentTerm == args.Term {
rf.state = StateFollower
DebugPrintf(dInfo, rf.me, "由候选者降级为追随者")
}
// 收到的任期大于自身,则追随该Leader
if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
rf.persist()
// 如果是Leader或候选人,则降级为Follower
if rf.state == StateLeader || rf.state == StateCandidate {
rf.state = StateFollower
DebugPrintf(dClient, rf.me, "收到的新的任期号Term%d,降级为Follower", rf.currentTerm)
}
}
// 检查Leader的PrevLogIndex是否小于SnapShotIndex
// 如果小于,则直接返回true,等待下一次同步日志
if args.PrevLogIndex < rf.LastIncludedIndex {
reply.Success = true
reply.Term = rf.currentTerm
return
}
// 检查Leader的日志是否与追随者相同
if args.PrevLogIndex > 0 && args.PrevLogIndex > rf.LastLogIndex() {
reply.Success = false
reply.Term = rf.currentTerm
//Extend: Follower的Log过短,并非发生冲突
reply.XLen = rf.LastLogIndex()
reply.XTerm = -1
reply.XIndex = 0
DebugPrintf(dInfo, rf.me, "日志Index不一致,收到PrevLogIndex:%d,rf.LastLogIndex=%d", args.PrevLogIndex, rf.LastLogIndex())
return
}
// 如果日志在PrevLogIndex中不包含Term与PrevLogTerm匹配的Entry,则回复false
if rf.LastLogIndex() > 0 && args.PrevLogIndex > 0 && args.PrevLogTerm != rf.GetLog(args.PrevLogIndex).Term {
reply.Success = false
reply.Term = rf.currentTerm
// Extend: 冲突信息
reply.XTerm = rf.GetLog(args.PrevLogIndex).Term
reply.XLen = rf.LastLogIndex()
reply.XIndex, _ = rf.TermRange(reply.XTerm)
DebugPrintf(dInfo, rf.me, "日志Term不一致,收到的PrevLogTerm: %d,MyPrevLogTerm: %d", args.PrevLogTerm, rf.GetLog(args.PrevLogIndex).Term)
return
}
for i, entry := range args.Entries {
// 第一个判断条件防止并发过程中有旧的数据被重新收到
// 第二个判断条件是截断未提交的过期数据
if rf.LastLogIndex() < args.PrevLogIndex+i+1 || rf.GetLog(args.PrevLogIndex+i+1).Term != entry.Term {
// 【修改】
rf.log = append(rf.GetLogSlice(rf.LastIncludedIndex+1, args.PrevLogIndex+i+1), args.Entries[i:]...)
rf.persist()
break
}
}
DebugPrintf(dInfo, rf.me, "Exist Entries: %v", rf.log)
// 5. 如果leaderCommit > commitIndex,则commitIndex设置为min(leaderCommit,最新Entry的索引)
if args.LeaderCommit > rf.commitIndex {
DebugPrintf(dInfo, rf.me, "收到Leader CommitIdx为%d", args.LeaderCommit)
// 不能超过Leader的Commit。如果Peer的Log比较滞后,args.PrevLogIndex+len(args.Entries)能快速更新commitIdx
rf.commitIndex = min(args.LeaderCommit, args.PrevLogIndex+len(args.Entries))
DebugPrintf(dCommit, rf.me, "更新CommitIdx为%d", rf.commitIndex)
}
reply.Term = rf.currentTerm
reply.Success = true
rf.resetElectionTime()
}
运行结果
Test (3D): snapshots basic ...
... Passed -- 9.3 3 548 213483 240
Test (3D): install snapshots (disconnect) ...
... Passed -- 64.1 3 1202 621766 300
Test (3D): install snapshots (disconnect+unreliable) ...
... Passed -- 92.7 3 1594 764054 336
Test (3D): install snapshots (crash) ...
labgob warning: Decoding into a non-default variable/field int may not work
... Passed -- 48.5 3 1052 609275 338
Test (3D): install snapshots (unreliable+crash) ...
... Passed -- 63.7 3 1118 639339 317
Test (3D): crash and restart all servers ...
... Passed -- 15.7 3 204 57418 45
Test (3D): snapshot initialization after crash ...
... Passed -- 5.4 3 68 18880 14
PASS
ok 6.5840/raft 299.426s