
基于Raft实现一个键值存储服务(kvraft)是理解分布式存储系统设计的核心实践。本文将结合MIT 6.5840课程的Lab 3C,逐步实现一个高可用的键值存储系统。
介绍
http://nil.csail.mit.edu/6.5840/2024/labs/lab-kvraft.html
在本实验中,您将使用 Lab 3 中的 Raft 库构建一个容错的键/值存储服务。您的键/值服务将是一个复制的状态机,由多个键/值服务器组成,每个服务器都维护一个键/值对的数据库,如 Lab 2 中所示,但额外使用 Raft 进行复制。只要大多数服务器存活并能通信,您的键/值服务应继续处理客户端请求,即使发生其他故障或网络分区。在 Lab 4 之后,您将实现 Raft 交互图 中所示的所有部分(Clerk、Service 和 Raft)。
客户端将以与Lab 2 非常相似的方式与您的键/值服务进行交互。具体来说,客户端可以向键/值服务发送三种不同的 RPC 调用:
- Put(key, value) : 替换数据库中特定键的值
- Append(key, arg) : 将参数附加到键的值(如果键不存在,则将现有值视为空字符串)
- Get(key) : 获取键的当前值(对于不存在的键返回空字符串)
键和值都是字符串。请注意,与实验 2 不同, Put 和 Append 都不应向客户端返回值。每个客户端通过一个带有 Put/Append/Get 方法的 Clerk 与Server 进行通信。
您的服务必须确保对 Clerk 的 Get/Put/Append 方法的调用是线性化的。如果逐个调用,Get/Put/Append 方法的行为应如同系统仅有一份状态副本,且每次调用都应观察到前序调用序列所隐含的状态修改。对于并发调用,返回值和最终状态必须与这些操作按某种顺序逐个执行时相同。如果调用在时间上重叠,则它们是并发的:例如,如果客户端 X 调用 Clerk.Put() ,客户端 Y 调用 Clerk.Append() ,然后客户端 X 的调用返回。一个调用必须观察到在它开始之前所有已完成调用的效果。
为单台服务器提供线性一致性相对容易。如果服务被复制,则难度更大,因为所有服务器必须为并发请求选择相同的执行顺序,必须避免使用未更新的状态回复客户端,并且必须在故障后以保留所有已确认客户端更新的方式恢复其状态。
本实验分为两部分。在 A 部分中,你将使用你的 Raft 实现来构建一个复制的键/值服务,但不使用快照。在 B 部分中,你将使用来自实验 3D 的快照实现,这将使 Raft 能够丢弃旧的日志条目。
Part A - 无快照的键/值服务
任务要求
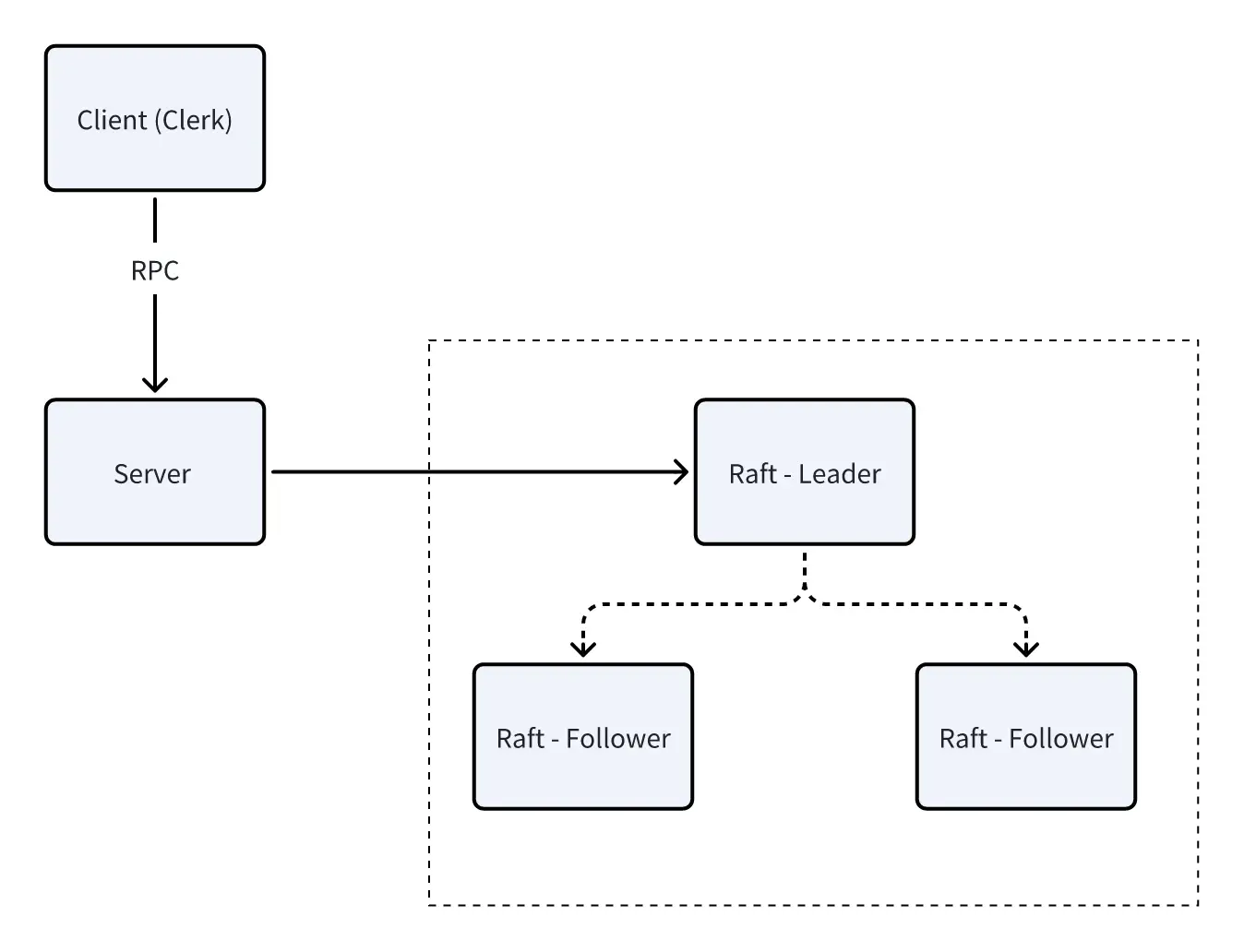
每个键/值服务器(“kvserver”)都将有一个关联的 Raft 对等体。Clerks 向关联 Raft 为领导者的 kvserver 发送操作RPC请求。kvserver 代码将操作提交给 Raft,以便 Raft 日志中保存一系列操作。所有 kvserver 按顺序执行 Raft 日志中的操作,将这些操作应用到它们的键/值数据库中;目的是让服务器维护键/值数据库的相同副本。
Clerk 有时不知道哪个 kvserver 是 Raft 领导者。如果 Clerk 向错误的 kvserver 发送 RPC,或者无法联系到该 kvserver, Clerk 应通过向不同的 kvserver 发送请求来重试。如果键/值服务将操作提交到其 Raft 日志(从而将操作应用到键/值状态机),领导者通过响应其 RPC 向 Clerk 报告结果。如果操作未能提交(例如,如果领导者被替换),服务器会报告错误, Clerk 则会尝试使用不同的服务器重试。
在网络和服务器故障的情况下,你将面临的一个问题是, Clerk 可能不得不多次发送 RPC,直到找到一个回复积极的 kvserver。如果领导者在将条目提交到 Raft 日志后立即失败, Clerk 可能不会收到回复,因此可能会将请求重新发送给另一个领导者。每次调用 Clerk.Put() 或 Clerk.Append() 应该只导致一次执行,因此你必须确保重新发送不会导致服务器执行请求两次。
任务:
- 你需要在 server.go 中实现 Put() 、 Append() 和 Get() RPC 处理程序。这些处理程序应使用 Start() 在 Raft 日志中输入一个 Op ;你应在 server.go 中填写 Op 结构体定义,以便描述 Put/Append/Get 操作。每个服务器应在 Raft 提交 Op 命令时执行它们,即当它们出现在 applyCh 上时。RPC 处理程序应注意到 Raft 提交其 Op 时,然后回复 RPC。
- 添加代码以处理故障,并应对重复的 Clerk 请求,包括 Clerk 在一个任期内向 kvserver 领导者发送请求、等待回复超时并在另一个任期内向新领导者重新发送请求的情况。请求应仅执行一次。这些注释包括重复检测的指导。
提示:
- 调用 Start() 后,您的 kvservers 需要等待 Raft 完成一致性协议。已达成一致的命令会到达 applyCh 。您的代码需要在 Put() 、 Append() 和 Get() 处理程序使用 Start() 向 Raft 日志提交命令时,持续读取 applyCh 。注意 kvserver 与其 Raft 库之间的死锁问题。
- 如果 kvserver 不是多数派的一部分,它不应完成 Get() RPC(以免提供过时数据)。一个简单的解决方案是将每个 Get() (以及每个 Put() 和 Append() )记录到 Raft 日志中。你无需实现第 8 节中描述的只读操作优化。
- 您不需要向 Raft ApplyMsg 或 Raft RPC(如 AppendEntries )添加任何字段,但您被允许这样做。
- 最好从一开始就添加锁定,因为避免死锁的需求有时会影响整体代码设计。使用 go test -race 检查你的代码是否无竞争。
- 您的解决方案需要处理这样一种情况:领导者已为 Clerk 的 RPC 调用了 Start(),但在请求被提交到日志之前失去了领导权。在这种情况下,您应安排 Clerk 将请求重新发送到其他服务器,直到找到新的领导者。一种实现方式是,服务器通过注意到 Raft 的任期已更改或 Start()返回的索引处出现了不同的请求,来检测自己是否已失去领导权。如果前任领导者自身被分区隔离,它将无法知晓新领导者的存在;但同一分区内的任何客户端也无法与新领导者通信,因此在这种情况下,服务器和客户端无限期等待直到分区恢复是可行的。
- 你可能需要修改你的 Clerk,使其记住上一次 RPC 中哪个服务器成为了领导者,并首先将下一个 RPC 发送到该服务器。这将避免在每次 RPC 时浪费时间寻找领导者,从而可能帮助你更快地通过某些测试。
- 您应采用类似于实验 2 中的重复检测机制。该机制应能迅速释放服务器内存,例如通过让每个 RPC 暗示客户端已收到其前一个 RPC 的回复。可以假设客户端一次只会向 Clerk 发起一个调用。您可能会发现,需要根据实验 2 的情况调整存储在重复检测表中的信息。
实现
根据任务的要求,我们需要实现一个无快照的键/值服务器。介绍中已经给了许多提示,总结一下,需要注意的点包括:
- 必须保证请求的幂等性
- Client需要寻找Leader服务
在Lab2中,我们已经实现了一个简单的键/值服务器,只不过没有接入Raft,因此我们可以借鉴Lab2中的代码,快速定义出Client。
Client初始化
为了保证幂等性,我们为Client结构体添加clerkId和nextReqId字段值,服务端能够根据这些字段判断是否为重复请求。此外,我们需要循环寻找Leader,为了能够加速找到Leader,我们可以增加一个字段lastLeader,记录上一次成功请求的Server序号。
type Clerk struct {
servers []*labrpc.ClientEnd
// You will have to modify this struct.
clerkId int64
nextReqId int64
lastLeader int64
}
代码框架中提供了nrand()函数,在初始化Client时,我们可以使用该函数生成clerkId。而对于nextReqId,我们实现如下方法来生成。nextId()方法可以返回1,2,…n序号。
func (ck *Clerk) nextId() int64 {
return atomic.AddInt64(&ck.nextReqId, 1)
}
Client的初始化函数如下,我们仅需为clerkId赋值即可,其余字段使用零值。
func MakeClerk(servers []*labrpc.ClientEnd) *Clerk {
ck := new(Clerk)
ck.servers = servers
// You'll have to add code here.
ck.clerkId = nrand()
return ck
}
Common部分
代码框架给出了Err定义,以及可选的常量。我们再添加“超时”常量,便于Client处理RPC请求。
const (
OK = "OK"
ErrNoKey = "ErrNoKey"
ErrWrongLeader = "ErrWrongLeader"
ErrTimeout = "ErrTimeout" // 新增
)
type Err string
我们需要为Get、Put、Append RPC的请求参数都加上clerkId和nextReqId,让Server判断重复,响应参数保持原样即可。
type PutAppendArgs struct {
Key string
Value string
// You'll have to add definitions here.
// Field names must start with capital letters,
// otherwise RPC will break.
ClerkID int64
ReqID int64
}
type GetArgs struct {
Key string
// You'll have to add definitions here.
ClerkID int64
ReqID int64
}
此外,我们可以补充常量,标记操作类型。
const (
OpTypeGet = "GET"
OpTypePut = "PUT"
OpTypeAppend = "APPEND"
)
RPC方法实现
Put方法与Append方法非常类似,共用一个实现即可,代码框架已经定义了。所以,我们仅需实现Get和PutAppend方法。需要注意的是,RPC请求失败的情况分为两种:
- RPC通信成功,Server返回响应值。
- RPC通信失败,Call方法返回false值。
无论哪种情况,请求失败都应该更换Server,不能死磕同一个Server,否则测试用例会无法通过。
当RPC请求成功后,需要更新lastLeader值。
func (ck *Clerk) PutAppend(key string, value string, op string) {
// You will have to modify this function.
args := PutAppendArgs{
Key: key,
Value: value,
ClerkID: ck.clerkId,
ReqID: ck.nextId(),
}
var reply PutAppendReply
serverId := int(atomic.LoadInt64(&ck.lastLeader))
for {
DPrintf("[Client] Ready to %s key:[%s] value:[%s] to S%d", op, key, value, serverId)
ok := ck.servers[serverId].Call("KVServer."+op, &args, &reply)
if !ok {
// 该Server可能已经宕机,尝试下一个
serverId = (serverId + 1) % len(ck.servers)
time.Sleep(50 * time.Millisecond)
continue
}
switch reply.Err {
case OK:
DPrintf("[Client] %s key:[%s] To S%d success", op, key, serverId)
atomic.SwapInt64(&ck.lastLeader, int64(serverId))
return
case ErrWrongLeader:
DPrintf("[Client] %s ,But Server %d is not Leader", op, serverId)
serverId = (serverId + 1) % len(ck.servers)
case ErrTimeout:
DPrintf("[Client] %s ,Server %d is Timeout", op, serverId)
}
time.Sleep(50 * time.Millisecond)
}
}
Get方法几乎一模一样,如下:
func (ck *Clerk) Get(key string) string {
// You will have to modify this function.
args := GetArgs{
Key: key,
ClerkID: ck.clerkId,
ReqID: ck.nextId(),
}
var reply GetReply
serverId := int(atomic.LoadInt64(&ck.lastLeader))
for {
ok := ck.servers[serverId].Call("KVServer.Get", &args, &reply)
if !ok {
// 该Server可能已经宕机,尝试下一个
serverId = (serverId + 1) % len(ck.servers)
time.Sleep(50 * time.Millisecond)
continue
}
switch reply.Err {
case OK:
DPrintf("[Client] Get key From Server%d:[%s] success, val:[%s]", serverId, key, reply.Value)
atomic.SwapInt64(&ck.lastLeader, int64(serverId))
return reply.Value
case ErrNoKey:
return ""
case ErrWrongLeader:
DPrintf("[Client] Server %d is not Leader", serverId)
serverId = (serverId + 1) % len(ck.servers)
case ErrTimeout:
DPrintf("[Client] Server %d is Timeout", serverId)
}
time.Sleep(50 * time.Millisecond)
}
}
Database实现
在实现Server之前,我们先需要实现一个简易的数据库,用于存储键值对。
数据可以使用map类型存储,操作map时要注意并发问题,因此需要加锁。由于数据库仅能由Server进行操作,所以加锁代码在实现Server时添加。
type Database struct {
Me int
DB map[string]string
}
func NewDatabase(me int) *Database {
return &Database{
Me: me,
DB: make(map[string]string),
}
}
func (s *Database) Get(key string) (string, Err) {
if val, ok := s.DB[key]; ok {
DPrintf("[Database%d] Get key:[%s] success, val:[%s]", s.Me, key, val)
return val, OK
}
return "", ErrNoKey
}
func (s *Database) Put(key string, value string) (string, Err) {
s.DB[key] = value
DPrintf("[Database%d] Put key:[%s] success, val:[%s]", s.Me, key, value)
return value, OK
}
func (s *Database) Append(key string, value string) (string, Err) {
if val, ok := s.DB[key]; ok {
s.DB[key] = val + value
} else {
s.DB[key] = value
}
DPrintf("[Database%d] Append key:[%s] success, val:[%s]", s.Me, key, s.DB[key])
return s.DB[key], OK
}
Server实现
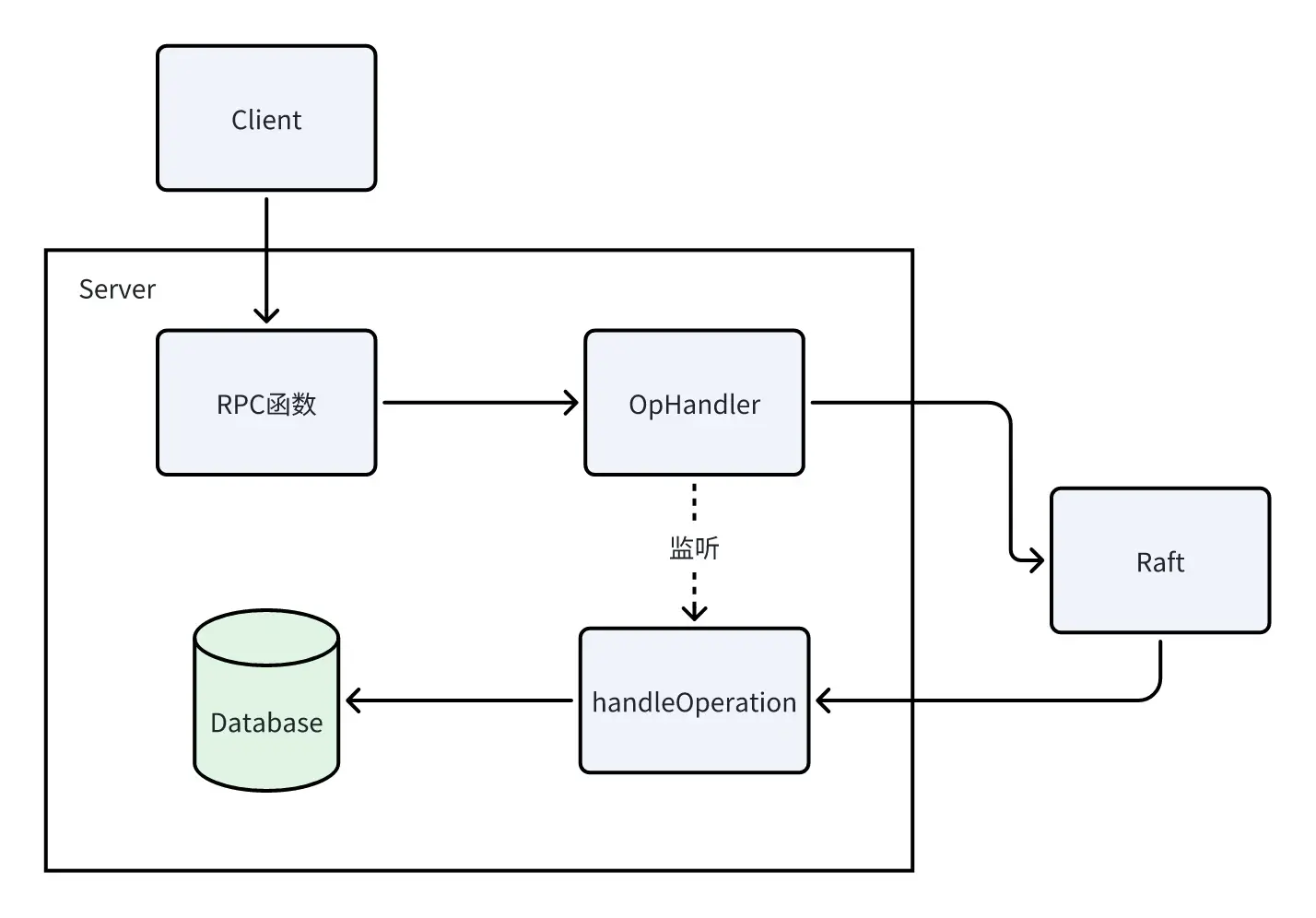
Server的实现如上图所示。接收到RPC请求时,需要将请求发送给OpHandler进行统一处理,OpHandler会将日志发送给Raft,Raft同步日志之后,会将“提交日志信息”返回给Server,handleOperation会处理“提交日志信息”,执行日志的操作之后会通知OpHandler,OpHandler最后将响应信息返回给RPC函数,Client最终收到响应,发送下一条RPC请求。
整体流程如上,但在细节部分,我们还需要实现“缓存”以及“监听通道”。“缓存”用于对请求去重。
Op结构体
Op是Server发送给Raft的日志信息,同样也是OpHandler方法的入参。在键值服务中,考虑到重复性问题,我们可以使用以下定义:
type Op struct {
// Your definitions here.
// Field names must start with capital letters,
// otherwise RPC will break.
Type string
Key string
Value string
ClerkID int64
ReqId int64
}
缓存AppliedMsg
缓存中记录了已经提交的Msg,实现缓存时需要注意不能占用太多内存,否则将无法通过测试。
对于同一个Client,RPC请求的ReqId是递增的,这意味只有Client成功请求一次RPC后才会进行下一次请求。所以我们在设计AppliedMsg时,仅需保存每个Client的最新请求结果,能极大减少内存占用。当请求的ReqId小于最新的ReqId,则返回false。
同样的,对AppliedLog操作需要加锁,由Server处理。
实现如下:
type AppliedMsg struct {
ReqId int64
Val string
}
type AppliedLog struct {
Applied map[int64]AppliedMsg
}
func (a *AppliedLog) Put(clerkId, reqId int64, val string) {
if a.Applied == nil {
a.Applied = make(map[int64]AppliedMsg)
}
if a.Applied[clerkId].ReqId >= reqId {
return
}
a.Applied[clerkId] = AppliedMsg{
ReqId: reqId,
Val: val,
}
}
func (a *AppliedLog) Get(clerkId, reqId int64) (string, bool) {
if a.Applied == nil {
return "", false
}
val, ok := a.Applied[clerkId]
if ok && val.ReqId == reqId {
return val.Val, true
}
return "", false
}
监听通道NotfiyCh
handleOperation在收到Raft提交的日志之后,将会往NotifyCh中添加消息,OpHandler接受消息并返回给Client。通道应该由OpHandler创建并删除。
type NotifyMsg struct {
Val string
Err Err
}
type NotifyCh struct {
m map[int64]map[int64]chan NotifyMsg // map[clerkId][reqId] -> chan
}
func (n *NotifyCh) Get(clerkId, reqId int64) chan NotifyMsg {
if n.m == nil {
return nil
}
if _, ok := n.m[clerkId]; ok {
if ch, ok := n.m[clerkId][reqId]; ok {
return ch
}
}
return nil
}
func (n *NotifyCh) Add(clerkId, reqId int64) chan NotifyMsg {
if n.m == nil {
n.m = make(map[int64]map[int64]chan NotifyMsg)
}
if _, ok := n.m[clerkId]; !ok {
n.m[clerkId] = make(map[int64]chan NotifyMsg)
}
ch := make(chan NotifyMsg, 1)
n.m[clerkId][reqId] = ch
return ch
}
func (n *NotifyCh) Delete(clerkId, reqId int64) {
if n.m == nil {
return
}
if _, ok := n.m[clerkId]; ok {
if _, ok := n.m[clerkId][reqId]; ok {
delete(n.m[clerkId], reqId)
}
}
}
Server初始化
我们需要实现StartKVServer函数,用户Server的初始化。handleOperation()方法应该由一个协程单独执行,后续详细讲述该方法的实现。
type KVServer struct {
mu sync.Mutex
me int
rf *raft.Raft
applyCh chan raft.ApplyMsg
dead int32 // set by Kill()
maxraftstate int // snapshot if log grows this big
// Your definitions here.
db *Database
notifyCh *NotifyCh
applied *AppliedLog
}
func StartKVServer(servers []*labrpc.ClientEnd, me int, persister *raft.Persister, maxraftstate int) *KVServer {
// call labgob.Register on structures you want
// Go's RPC library to marshall/unmarshall.
labgob.Register(Op{})
kv := new(KVServer)
kv.me = me
kv.maxraftstate = maxraftstate
// You may need initialization code here.
kv.applyCh = make(chan raft.ApplyMsg)
kv.rf = raft.Make(servers, me, persister, kv.applyCh)
// You may need initialization code here.
kv.db = NewDatabase(kv.me)
kv.notifyCh = &NotifyCh{}
kv.applied = &AppliedLog{}
go kv.handleOperation()
return kv
}
OpHandler
在将操作日志发送给Raft时,首先应该检测缓存中是否已经存在。如果不存在,则新建消息通道。此处,我设置了1s的等待的时间,1s之内如果无消息返回,则删除通道并向客户端响应错误。
func (kv *KVServer) opHandler(op Op) (string, Err) {
// Your code here.
// 初步去重
kv.mu.Lock()
val, ok := kv.applied.Get(op.ClerkID, op.ReqId)
if ok {
kv.mu.Unlock()
return val, OK
}
ch := kv.notifyCh.Add(op.ClerkID, op.ReqId)
kv.mu.Unlock()
defer func() {
kv.mu.Lock()
defer kv.mu.Unlock()
kv.notifyCh.Delete(op.ClerkID, op.ReqId)
}()
// 提交到Raft
_, _, isLeader := kv.rf.Start(op)
if !isLeader {
return "", ErrWrongLeader
}
DPrintf("[Server%d] Raft Start handle [%s], key:[%s] value:[%s]", kv.me, op.Type, op.Key, op.Value)
timer := time.NewTimer(1000 * time.Millisecond)
defer timer.Stop()
select {
case <-timer.C:
DPrintf("[Server%d] handle [%s] Timeout, key:[%s] value:[%s]", kv.me, op.Type, op.Key, op.Value)
return "", ErrTimeout
case msg := <-ch:
if msg.Err != OK {
return "", msg.Err
}
DPrintf("[Server%d] handle [%s] Success, key:[%s] value:[%s]", kv.me, op.Type, op.Key, op.Value)
return msg.Val, OK
}
}
RPC方法
与Client中的Put和Append一样,我们将两种操作类型合并为putAppend,简化代码。
func (kv *KVServer) Get(args *GetArgs, reply *GetReply) {
// Your code here.
op := Op{
Type: OpTypeGet,
Key: args.Key,
Value: "",
ClerkID: args.ClerkID,
ReqId: args.ReqID,
}
val, err := kv.opHandler(op)
if err != OK {
DPrintf("[Server%d] Raft Operate Get [%s] Failed,Err: %s", kv.me, args.Key, err)
reply.Err = err
return
}
DPrintf("[Server%d] Raft Operate Get [%s] Success, current Val: [%s]", kv.me, args.Key, val)
reply.Value = val
reply.Err = OK
return
}
func (kv *KVServer) putAppend(opType string, args *PutAppendArgs, reply *PutAppendReply) {
op := Op{
Type: opType,
Key: args.Key,
Value: args.Value,
ClerkID: args.ClerkID,
ReqId: args.ReqID,
}
val, err := kv.opHandler(op)
if err != OK {
DPrintf("[Server%d] Raft Operate %s [%s] Failed,Err: %s", kv.me, opType, args.Key, err)
reply.Err = err
return
}
DPrintf("[Server%d] Raft Operate %s [%s] Success, current val:[%s]", kv.me, opType, args.Key, val)
reply.Err = OK
return
}
func (kv *KVServer) Put(args *PutAppendArgs, reply *PutAppendReply) {
// Your code here.
kv.putAppend(OpTypePut, args, reply)
}
func (kv *KVServer) Append(args *PutAppendArgs, reply *PutAppendReply) {
// Your code here.
kv.putAppend(OpTypeAppend, args, reply)
}
handleOperation
该函数接收到日志信息后,首先需要进行去重,如果不去重将会导致错误,例如,当Client的执行命令到达Server时,Server处理时间较长,Client超时,因此没有将命令结果缓存,Client重新请求,Server会处理两条一模一样的命令,而handleOperation处理完成一条命令之后,便会关闭通道,由于handleOperation没有进行去重,通道会被关闭2遍,导致出错。
需要注意的是,并非每次处理的msg都存在消息通道,只有Leader收到Client请求之后,才会创建消息通道,而对于Follower而言,只会接收到msg信息,无需向通道响应。
此外,当数据库操作成功之后,就必须将结果保存在缓存中,即要保证操作的原子性。之前我将“添加缓存”逻辑放在OpHandler中,便出现了错误,因为超时后,已保存至数据库的数据没有保存在缓存中,导致重试时会再次更新数据库,破坏了幂等性。
func (kv *KVServer) handleOperation() {
for !kv.killed() {
msg := <-kv.applyCh
if msg.CommandValid {
op := msg.Command.(Op)
DPrintf("[Server%d] Raft Apply [%s], key:[%s] value:[%s]", kv.me, op.Type, op.Key, op.Value)
var (
val string
err Err
)
kv.mu.Lock()
// 去重
if _, ok := kv.applied.Get(op.ClerkID, op.ReqId); ok {
kv.mu.Unlock()
DPrintf("[Server%d] Already Applied [%s], key:[%s]", kv.me, op.Type, op.Key)
continue
}
switch op.Type {
case OpTypeGet:
val, err = kv.db.Get(op.Key)
case OpTypePut:
val, err = kv.db.Put(op.Key, op.Value)
case OpTypeAppend:
val, err = kv.db.Append(op.Key, op.Value)
}
ch := kv.notifyCh.Get(op.ClerkID, op.ReqId)
if err == OK {
kv.applied.Put(op.ClerkID, op.ReqId, val)
}
kv.mu.Unlock()
DPrintf("[Server%d] Get NotifyCh Done ,Op:[%s], key:[%s], ChIsNil:[%v]", kv.me, op.Type, op.Key, ch == nil)
if ch != nil {
ch <- NotifyMsg{
Val: val,
Err: err,
}
DPrintf("[Server%d] Notify Clerk [%d] Req [%d] Done,Op:[%s], key:[%s] value:[%s]",
kv.me, op.ClerkID, op.ReqId, op.Type, op.Key, op.Value)
close(ch)
}
}
}
}
运行结果
Test: one client (4A) ...
... Passed -- 15.1 5 3341 659
Test: ops complete fast enough (4A) ...
... Passed -- 22.5 3 3042 0
Test: many clients (4A) ...
... Passed -- 15.8 5 7385 1447
Test: unreliable net, many clients (4A) ...
... Passed -- 16.0 5 5270 930
Test: concurrent append to same key, unreliable (4A) ...
... Passed -- 2.2 3 208 52
Test: progress in majority (4A) ...
... Passed -- 1.3 5 69 2
Test: no progress in minority (4A) ...
... Passed -- 1.1 5 97 3
Test: completion after heal (4A) ...
... Passed -- 1.1 5 45 3
Test: partitions, one client (4A) ...
... Passed -- 23.1 5 12402 453
Test: partitions, many clients (4A) ...
... Passed -- 23.6 5 7438 1376
Test: restarts, one client (4A) ...
... Passed -- 22.4 5 3514 661
Test: restarts, many clients (4A) ...
... Passed -- 22.4 5 7952 1430
Test: unreliable net, restarts, many clients (4A) ...
... Passed -- 23.8 5 5546 832
Test: restarts, partitions, many clients (4A) ...
... Passed -- 29.9 5 7142 1237
Test: unreliable net, restarts, partitions, many clients (4A) ...
... Passed -- 30.4 5 3480 440
Test: unreliable net, restarts, partitions, random keys, many clients (4A) ...
... Passed -- 33.4 7 9368 837
PASS
ok 6.5840/kvraft 286.255s
Part B - 带快照的键/值服务
任务要求
就目前情况而言,键/值服务器并未调用 Raft 库的 Snapshot() 方法,重启的服务器必须重放完整的持久化 Raft 日志以恢复其状态。现在,您将修改 kvserver,使其与 Raft 协作,利用 Lab 3D 中的 Raft Snapshot() 来节省日志空间,并减少重启时间。
测试者将 maxraftstate 传递给你的 StartKVServer() 。 maxraftstate 表示你的持久化 Raft 状态的最大允许大小(以字节为单位,包括日志,但不包括快照)。你应该将 maxraftstate 与 persister.RaftStateSize() 进行比较。每当你的键/值服务器检测到 Raft 状态大小接近此阈值时,应通过调用 Raft 的 Snapshot 来保存快照。如果 maxraftstate 为-1,则无需进行快照。 maxraftstate 适用于你的 Raft 作为第一个参数传递给 persister.Save() 的 GOB 编码字节。
任务:
修改你的 kvserver,使其能够检测到持久化的 Raft 状态变得过大时,向 Raft 传递一个快照。当 kvserver 服务器重启时,它应从 persister 读取快照并从快照中恢复其状态。
提示:
- 考虑一下 kvserver 应该在何时对其状态进行快照,以及快照中应包含哪些内容。Raft 使用 Save() 将每个快照存储在 persister 对象中,同时保存相应的 Raft 状态。你可以使用 ReadSnapshot() 读取最新存储的快照。
- 您的 kvserver 必须能够检测跨检查点的日志中的重复操作,因此用于检测它们的任何状态都必须包含在快照中。
- 将快照中存储的结构的所有字段大写。
- 你的 Raft 库可能存在本实验暴露的 bug。如果对 Raft 实现进行了修改,请确保它仍能通过所有 Lab 3 测试。
- 进行实验 4 测试的合理时间应为 400 秒的实际时间和 700 秒的 CPU 时间。此外, go test -run TestSnapshotSize 应少于 20 秒的实际时间。
实现
我们需要记录最后一次快照的CommandIndex,用来判断快照请求是否过期,避免加载了过期的快照信息,因此Server结构体需要新增lastApplied属性值。Server应该持久化Database、Applied和LastApplied状态信息,便于宕机重启后能恢复之前的状态。
Server初始化
在结构体中新增lastApplied、persister。正如任务要求,需要使用persister.RaftStateSize()值与maxraftstate进行比较。
type KVServer struct {
mu sync.Mutex
me int
rf *raft.Raft
applyCh chan raft.ApplyMsg
dead int32 // set by Kill()
maxraftstate int // snapshot if log grows this big
// Your definitions here.
db *Database
notifyCh *NotifyCh
applied *AppliedLog
lastApplied int
persister *raft.Persister
}
初始化方法新增加载快照,具体实现见后续。
func StartKVServer(servers []*labrpc.ClientEnd, me int, persister *raft.Persister, maxraftstate int) *KVServer {
// call labgob.Register on structures you want
// Go's RPC library to marshall/unmarshall.
labgob.Register(Op{})
kv := new(KVServer)
kv.me = me
kv.maxraftstate = maxraftstate
// You may need initialization code here.
kv.applyCh = make(chan raft.ApplyMsg)
kv.rf = raft.Make(servers, me, persister, kv.applyCh)
// You may need initialization code here.
kv.db = NewDatabase(kv.me)
kv.notifyCh = &NotifyCh{}
kv.applied = &AppliedLog{}
kv.persister = persister // 4B
kv.LoadSnapShot(persister.ReadSnapshot()) //4B
go kv.handleOperation()
return kv
}
SnapShot
“生成快照”和“加载快照”的方法将状态信息与快照互转。
func (kv *KVServer) GenSnapShot() []byte {
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
if err := e.Encode(kv.db); err != nil {
DPrintf("[Server%d] GenSnapShot Encode DB Failed, Err: %v", kv.me, err)
return nil
}
if err := e.Encode(kv.applied); err != nil {
DPrintf("[Server%d] GenSnapShot Encode Applied Failed, Err: %v", kv.me, err)
return nil
}
if err := e.Encode(kv.lastApplied); err != nil {
DPrintf("[Server%d] GenSnapShot Encode LastApplied Failed, Err: %v", kv.me, err)
return nil
}
data := w.Bytes()
return data
}
同理,将三个状态信息反序列化之后,替代Server的属性值。
func (kv *KVServer) LoadSnapShot(snapShot []byte) {
if len(snapShot) == 0 {
return
}
r := bytes.NewBuffer(snapShot)
d := labgob.NewDecoder(r)
var (
db Database
applied AppliedLog
lastApplied int
)
if err := d.Decode(&db); err != nil {
DPrintf("[Server%d] LoadSnapShot Decode DB Failed, Err: %v", kv.me, err)
return
}
if err := d.Decode(&applied); err != nil {
DPrintf("[Server%d] LoadSnapShot Decode Applied Failed, Err: %v", kv.me, err)
return
}
if err := d.Decode(&lastApplied); err != nil {
DPrintf("[Server%d] LoadSnapShot Decode LastApplied Failed, Err: %v", kv.me, err)
return
}
kv.db = &db
kv.applied = &applied
kv.lastApplied = lastApplied
}
handleOperation
添加处理快照的逻辑。当从Raft中收到的msg为SnapShot类型时,判断是否为过期信息,如果不是,则更新自身状态为快照信息。对于Command消息,每次成功处理之后都需要更新lastApplied值。
任务要求我们RaftStateSize()接近maxraftstate进行快照,我将执行快照的阈值设置为0.9* maxraftstate。
func (kv *KVServer) handleOperation() {
for !kv.killed() {
msg := <-kv.applyCh
if msg.CommandValid {
op := msg.Command.(Op)
DPrintf("[Server%d] Raft Apply [%s], key:[%s] value:[%s]", kv.me, op.Type, op.Key, op.Value)
var (
val string
err Err
)
kv.mu.Lock()
// 去重
if _, ok := kv.applied.Get(op.ClerkID, op.ReqId); ok {
kv.mu.Unlock()
DPrintf("[Server%d] Already Applied [%s], key:[%s]", kv.me, op.Type, op.Key)
continue
}
switch op.Type {
case OpTypeGet:
val, err = kv.db.Get(op.Key)
case OpTypePut:
val, err = kv.db.Put(op.Key, op.Value)
case OpTypeAppend:
val, err = kv.db.Append(op.Key, op.Value)
}
ch := kv.notifyCh.Get(op.ClerkID, op.ReqId)
if err == OK {
kv.lastApplied = msg.CommandIndex //4B
kv.applied.Put(op.ClerkID, op.ReqId, val)
}
kv.mu.Unlock()
DPrintf("[Server%d] Get NotifyCh Done ,Op:[%s], key:[%s], ChIsNil:[%v]", kv.me, op.Type, op.Key, ch == nil)
if ch != nil {
ch <- NotifyMsg{
Val: val,
Err: err,
}
DPrintf("[Server%d] Notify Clerk [%d] Req [%d] Done,Op:[%s], key:[%s] value:[%s]",
kv.me, op.ClerkID, op.ReqId, op.Type, op.Key, op.Value)
close(ch)
}
// 判断是否需要生成快照
size := kv.persister.RaftStateSize()
if kv.maxraftstate != -1 && size >= int(float64(kv.maxraftstate)*0.9) {
DPrintf("[Server%d] RaftStateSize:[%d] >= MaxRaftState:[%d], Start GenSnapShot", kv.me, size, kv.maxraftstate)
kv.mu.Lock()
data := kv.GenSnapShot()
kv.rf.Snapshot(msg.CommandIndex, data)
kv.mu.Unlock()
}
} else if msg.SnapshotValid {
DPrintf("[Server%d] Raft Apply Snapshot, Index:[%d]", kv.me, msg.SnapshotIndex)
kv.mu.Lock()
if msg.SnapshotIndex >= kv.lastApplied {
kv.LoadSnapShot(msg.Snapshot)
kv.lastApplied = msg.SnapshotIndex
}
kv.mu.Unlock()
}
}
}
运行结果
Test: InstallSnapshot RPC (4B) ...
labgob warning: Decoding into a non-default variable/field Err may not work
... Passed -- 5.3 3 258 63
Test: snapshot size is reasonable (4B) ...
... Passed -- 17.9 3 2430 800
Test: ops complete fast enough (4B) ...
... Passed -- 21.9 3 3034 0
Test: restarts, snapshots, one client (4B) ...
... Passed -- 22.5 5 3578 672
Test: restarts, snapshots, many clients (4B) ...
... Passed -- 23.9 5 55081 10494
Test: unreliable net, snapshots, many clients (4B) ...
... Passed -- 16.3 5 4925 815
Test: unreliable net, restarts, snapshots, many clients (4B) ...
... Passed -- 24.2 5 6327 988
Test: unreliable net, restarts, partitions, snapshots, many clients (4B) ...
... Passed -- 30.4 5 4888 723
Test: unreliable net, restarts, partitions, snapshots, random keys, many clients (4B) ...
... Passed -- 31.5 7 12197 1167
PASS
ok 6.5840/kvraft 193.948s