

本文将介绍MIT6.5840的Lab5的核心功能实现,完整代码见Github。
https://github.com/bestzy6/MIT6.5840
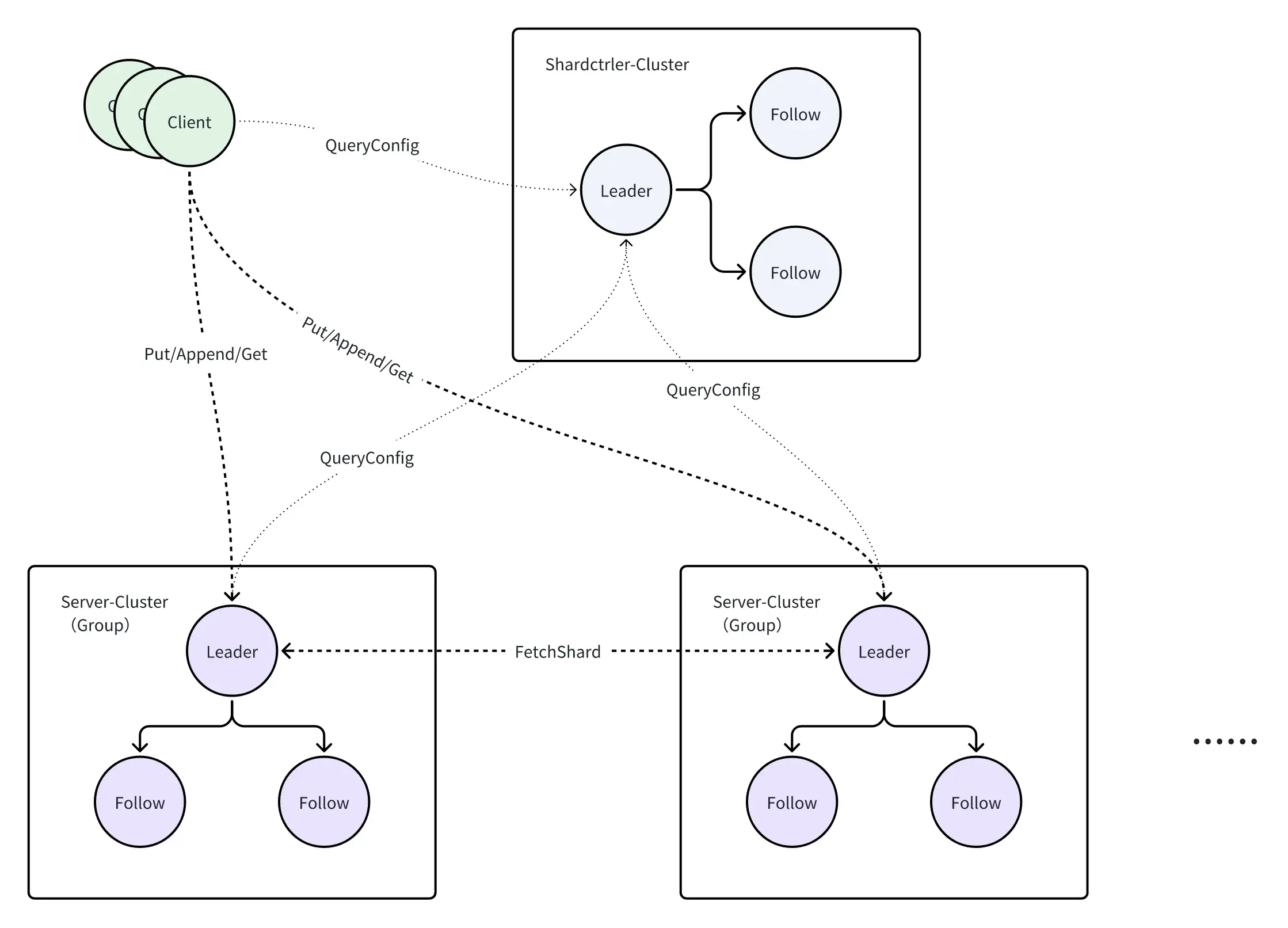
整个Lab5中,各部分的关系如下图所示。Shardctrler-Cluster存储了配置情况,Client和Server从中获取配置并完成一系列逻辑操作。
Lab5A
ShardCtrler代码实现
ShardCtrler几乎可以无脑复制Lab4的代码,Client与Server的主要流程是一致的,同样需要注意去重,RPC请求需要增加ClerkID与ReqID,但无需考虑快照。此文只讲解核心实现,具体可参考代码。
Op结构体如下:
type Op struct {
// Your data here.
Type string
Servers map[int][]string //Join
GIDs []int //Leave
Shard int //Move
GID int //Move
Num int //Query
ClerkId int64
ReqId int64
}
相较于Lab4,handleOperation方法中的数据库操作变更为opExecutor,代码如下:
func (sc *ShardCtrler) opExecutor(op Op) (Config, Err) {
var (
cfg Config
err Err
)
switch op.Type {
case Join:
cfg, err = sc.joinExecutor(op)
sc.configs = append(sc.configs, cfg)
return cfg, err
case Leave:
cfg, err = sc.leaveExecutor(op)
sc.configs = append(sc.configs, cfg)
return cfg, err
case Move:
cfg, err = sc.moveExecutor(op)
sc.configs = append(sc.configs, cfg)
return cfg, err
case Query:
cfg, err = sc.queryExecutor(op)
return cfg, err
}
return Config{}, OK
}
根据任务要求,在进行Join、Leave操作后需要负载均衡处理。以下解释4个操作逻辑。
Join&Leave
Join RPC 由管理员用于添加新的副本组。其参数是一组从唯一且非零的副本组标识符(GIDs)到服务器名称列表的映射。shardctrler 应通过创建包含新副本组的新配置来响应。新配置应尽可能均匀地在所有组之间分配分片,并且应尽可能少地移动分片以实现该目标。如果 GID 不是当前配置的一部分,shardctrler 应允许重新使用 GID(即,应允许 GID 先加入,然后离开,再重新加入)。
Leave RPC 的参数是之前加入的组的 GID 列表。shardctrler 应创建一个不包含这些组的新配置,并将这些组的分片分配给剩余的组。新配置应尽可能均匀地在组之间分配分片,并应尽可能少地移动分片以实现该目标。
选取最后的配置并加入或移除Group,操作后的负载均衡后续进行详解。
需要注意的是,新配置的map必须深拷贝,否则当前的变动会影响到之前的配置。以下给出Join的代码,Leave与Join相似。
func (sc *ShardCtrler) joinExecutor(op Op) (Config, Err) {
var (
servers = op.Servers //GID -> 服务名称
cfgNum = len(sc.configs)
lastCfg = sc.configs[cfgNum-1]
)
// 深拷贝,创建新的Groups
DPrintf("[Server%d] %v Join, Origin Shards:%v", sc.me, servers, lastCfg.Shards)
newGroups := make(map[int][]string, len(lastCfg.Groups))
for gid, srvs := range lastCfg.Groups {
var (
newServices = make([]string, 0, len(srvs)) // 服务名称
ServicesMap = make(map[string]struct{}, len(srvs)) // 服务名称Set,用于去重
)
for _, srv := range srvs {
newServices = append(newServices, srv)
ServicesMap[srv] = struct{}{}
}
if tmpServices, ok := servers[gid]; ok {
for _, tmpService := range tmpServices {
// 判断是否重复
if _, exist := ServicesMap[tmpService]; exist {
continue
}
newServices = append(newServices, tmpService)
}
// 删除GID,表示已经添加
delete(servers, gid)
}
newGroups[gid] = newServices
}
// 如果servers中的GID在原组中不存在,则servers长度不为0
for gid, srvs := range servers {
newGroups[gid] = srvs
}
DPrintf("[Server%d] %v Join newGroups: %v", sc.me, servers, newGroups)
shards := NewBalancer(sc.me).ReBalanceShards(lastCfg.Shards, newGroups)
DPrintf("[Server%d] %v Join balanced Shards: %v", sc.me, servers, shards)
return Config{
Num: cfgNum,
Shards: shards,
Groups: newGroups,
}, OK
}
Move
Move RPC 的参数是一个分片编号和一个 GID。shardctrler 应创建一个新配置,将分片分配给该组。 Move 的目的是让我们能够测试您的软件。在 Move 之后的 Join 或 Leave 可能会撤销 Move ,因为 Join 和 Leave 会重新平衡。
并没有需要特别注意的点,与Join&Leave一样深拷贝Groups字段即可。
func (sc *ShardCtrler) moveExecutor(op Op) (Config, Err) {
var (
shard = op.Shard
gid = op.GID
cfgNum = len(sc.configs)
cfg = sc.configs[cfgNum-1]
)
// 深拷贝
newGroups := make(map[int][]string, len(cfg.Groups))
for id, srvs := range cfg.Groups {
newSrvs := make([]string, len(srvs))
copy(newSrvs, srvs)
newGroups[id] = newSrvs
}
var newShards [NShards]int
for i := range cfg.Shards {
if i == shard {
newShards[i] = gid
continue
}
newShards[i] = cfg.Shards[i]
}
newConfig := Config{
Num: cfgNum,
Shards: newShards,
Groups: newGroups,
}
return newConfig, OK
}
Query
Query RPC 的参数是一个配置编号。shardctrler 会回复具有该编号的配置。如果编号为 -1 或大于已知的最大配置编号,shardctrler 应回复最新的配置。 Query(-1) 的结果应反映 shardctrler 在接收 Query(-1) RPC 之前完成处理的每个 Join 、 Leave 或 Move RPC。
用于查询指定编号的配置。根据任务的要求,如果序号传入-1或者大于配置号,则返回最新的配置。
func (sc *ShardCtrler) queryExecutor(op Op) (Config, Err) {
cfg := sc.configs[len(sc.configs)-1]
num := op.Num
if num < 0 || num >= len(sc.configs) {
return cfg, OK
}
return sc.configs[num], OK
}
ShardCtrler负载均衡
Lab5A中的难点是实现负载均衡。假设存在4个Group,以及10个Shard,将Group按照Shard数量倒序排序,此时负载状态如下图所示:
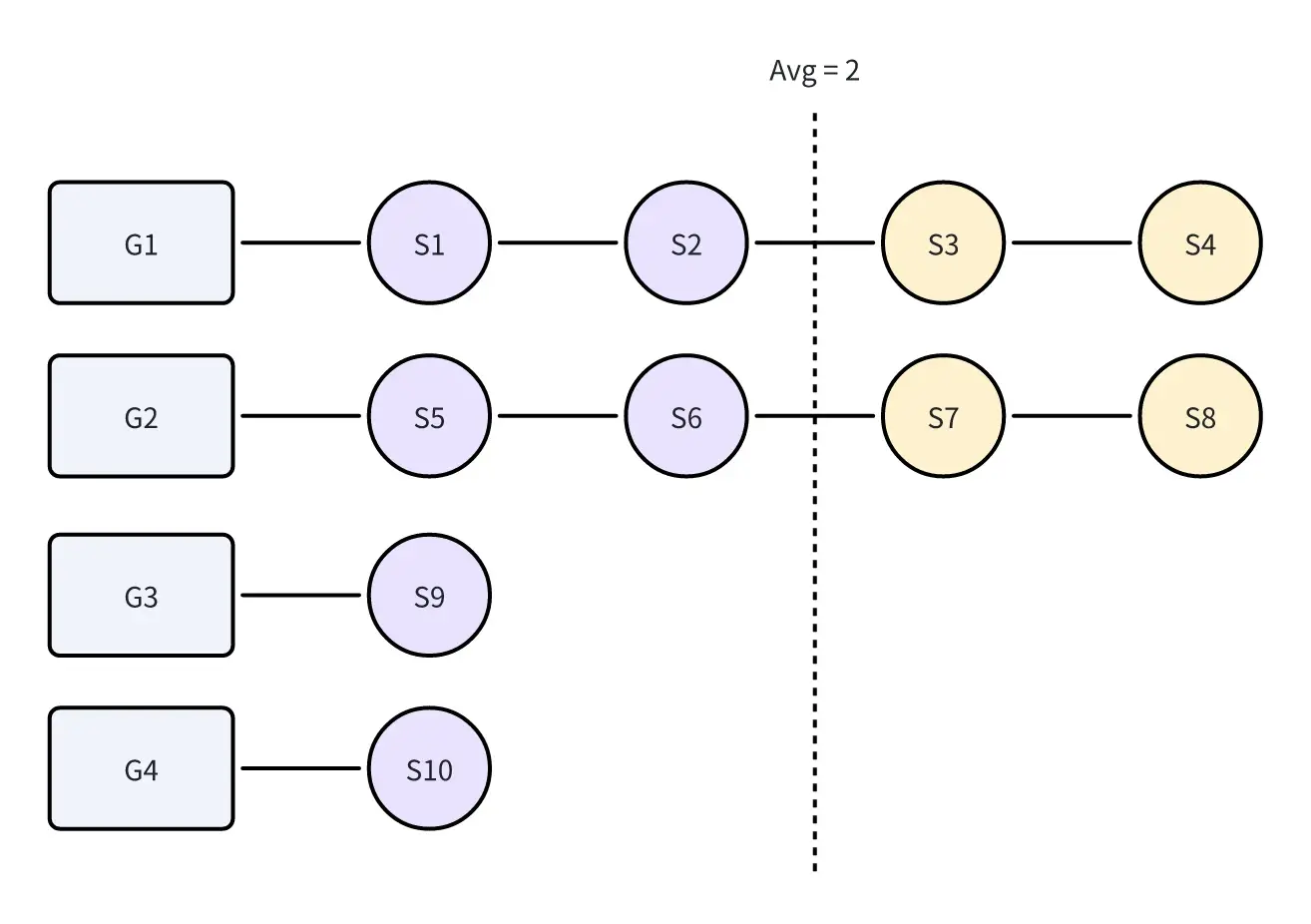
显然Group的平均Shard数为2(10/4=2)。如果我们将Group中大于Avg的Shard截取,再将截取的Shard分配给Shard数量小于等于Avg的Group中,那么以上负载状态将会多出2个Shard,如下图所示:
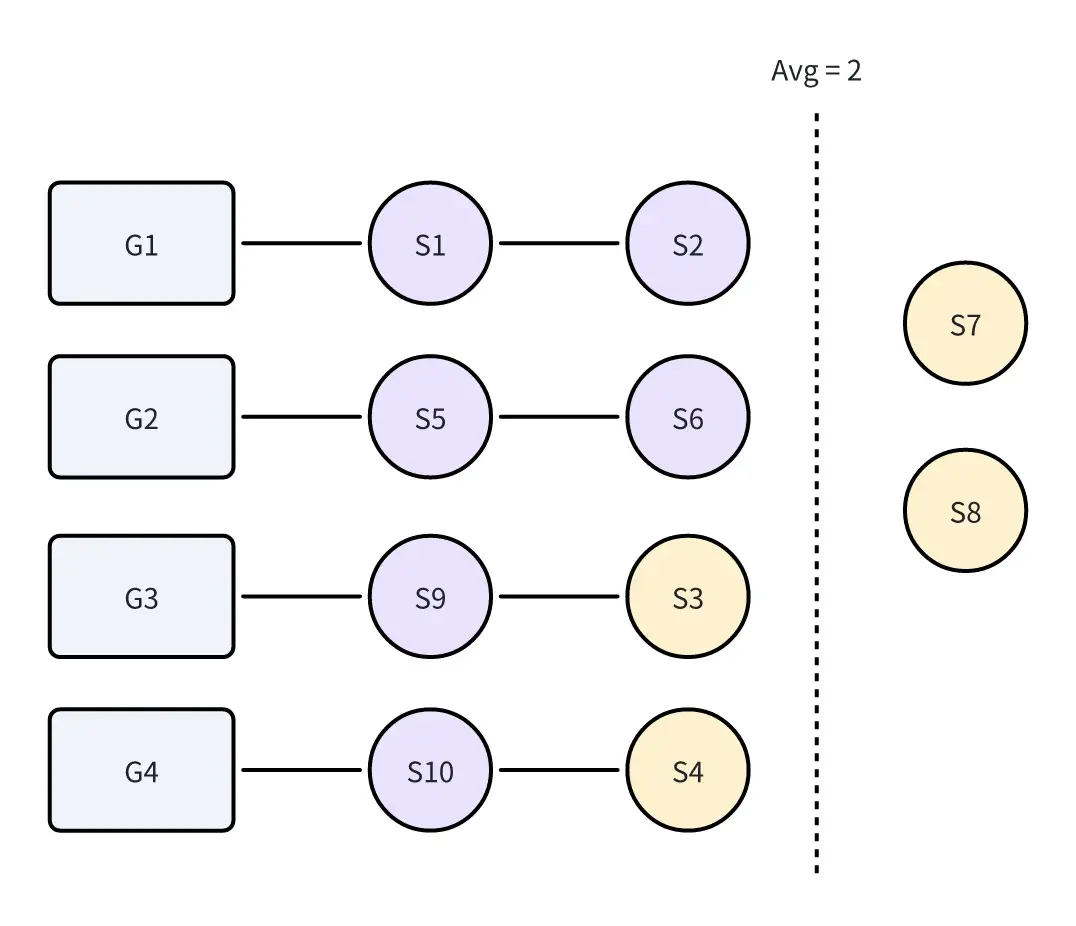
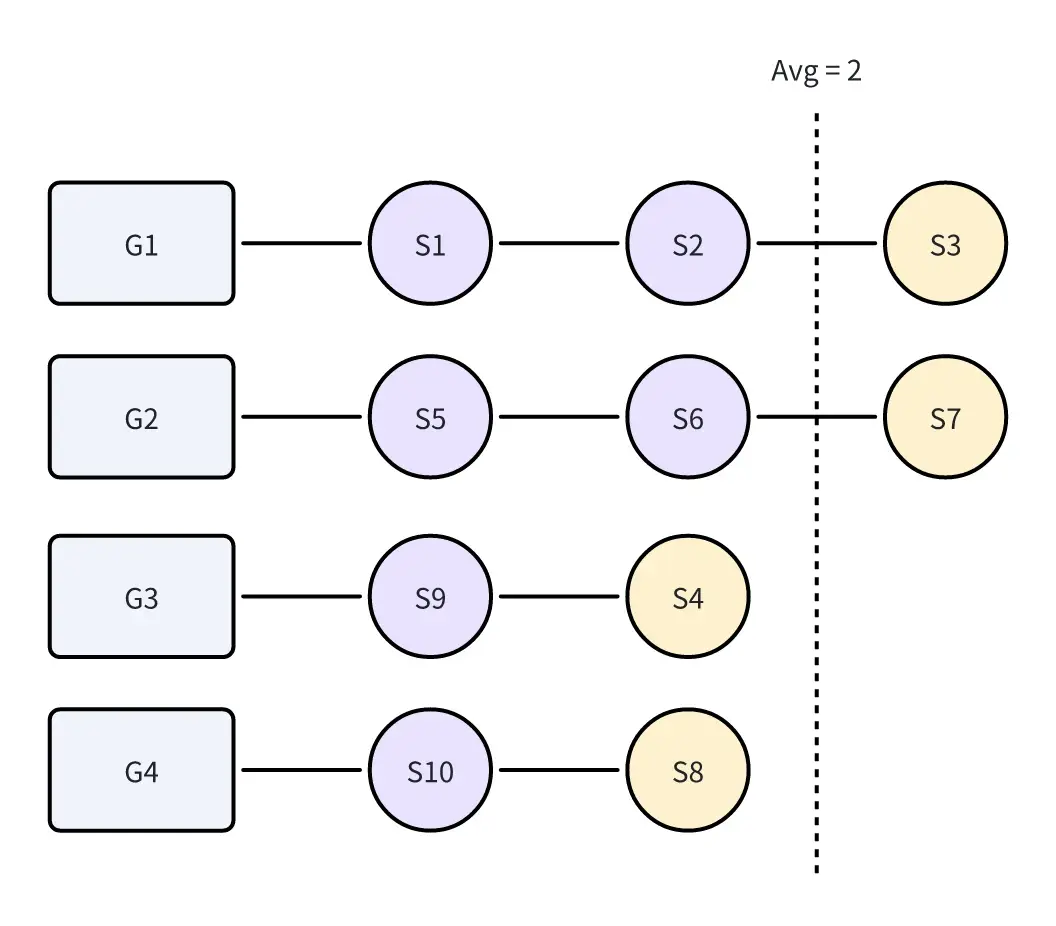
我们的目标是使Shard尽可能不移动,因此最佳的负载状态是S3和S4保持原样,而S7和S8移动至G3、G4。此时负载状态为:
要使Group达到如上负载均衡,一种朴素的方法是求出Shard平均值,以及Shard取模,基于模长,动态调整Group的最大Shard值,保证各个Group所分配的最大与最小Shard数量差值为1。具体做法如下:
- 求出Avg,上述情况为
10 / 4 = 2 - 求出Mod,上述情况为
10 % 4 = 2 - 将Group序列中前
Mod个Group的保留长度设置为Avg + 1,其余Group的保留长度为Avg。
Balancer
为保证单一原则,我们将负载均衡逻辑抽离。Balancer结构体(类)是负载均衡处理器。
type Balancer struct {
me int
}
func NewBalancer(me int) *Balancer {
return &Balancer{
me: me,
}
}
Balancer实现了ReBalanceShards方法,该方法要求传入最后一个配置的Shard数组oldShards,以及最新的Groups。逻辑步骤如下:
- 创建Group-Shard链表结构
grpShardMap,表示Group负责的Shard序号,其中Key为GID,而Value为Shard切片,注意切片按照Shard序号顺序排序。 - 将Group按照Shard数量倒序排序,Shard数量一致时按GID顺序排序,以此保证排序结果的稳定性。
- 筛选出需要休眠的Group,即排序序号大于等于
NShards数量的Group。因为这些Group无法分到Shard。 - 将“超出Group容量的Shard”、“休眠Group的所有Shard”放置在
freeShards中,freeShards属于自定义Set类型,具体参考代码。 - 将
freeShards排序,按序列放到未超容量的Group中。 - 根据
grpShardMap重新生成Shards数组。
func (b *Balancer) ReBalanceShards(oldShards [NShards]int, groups map[int][]string) [NShards]int {
if len(groups) == 0 {
return [NShards]int{}
}
// 初始情况下,不存在GID的Shard应该归属于0
// oldShards可能被分配至已经不存在的Group
grpShardMap, freeShards := b.groupShardMap(oldShards, groups)
sortedGid := b.sortGroupByShard(grpShardMap)
sleepGid := b.getSleepGid(sortedGid)
DPrintf("[Server%d] ReBalanceShards sortedGid:%v ; sleepGid:%v ; freeShards: %v", b.me, sortedGid, sleepGid, freeShards)
// 计算Shard平均数量,平均值最小为1
avgShardNum := NShards / (len(sortedGid) - sleepGid.Len())
modShardNum := NShards % (len(sortedGid) - sleepGid.Len())
// 将超过平均值的Shard放置在freeShards中
for i, gid := range sortedGid {
shards := grpShardMap[gid]
// 如果GID在sleepGid中,则将Shard放置在freeShards中
if sleepGid.Contain(gid) {
freeShards.Add(shards...)
continue
}
// 计算当前GID应该拥有的Shard数量
var pos int
if i < modShardNum {
pos = avgShardNum + 1
} else {
pos = avgShardNum
}
// 如果Shard数量大于pos值,则将多余的Shard放置在freeShards中
if len(shards) > pos {
freeShards.Add(shards[pos:]...)
grpShardMap[gid] = shards[:pos]
}
}
// 保证每次分配Shard时取出的Shard是有序的,以此确保副本的一致性
unAsgnShards := freeShards.SortedSlice()
// 重新分配Shards
for i, gid := range sortedGid {
if sleepGid.Contain(gid) {
continue
}
shards := grpShardMap[gid]
var pos int
if i < modShardNum {
pos = avgShardNum + 1
} else {
pos = avgShardNum
}
// 如果Shard数量小于平均值,则从unAsgnShards中取出Shard进行分配
for len(shards) < pos {
if len(unAsgnShards) == 0 {
break
}
shards = append(shards, unAsgnShards[0])
unAsgnShards = unAsgnShards[1:]
}
grpShardMap[gid] = shards
}
DPrintf("[Server%d] ReBalanceShards grpShardMap: %v", b.me, grpShardMap)
shards := b.genNShards(grpShardMap)
return shards
}
Server核心代码实现
代码整体上与Lab4相同,具体的可参考代码仓库 。
更新配置
Server的Op结构体如下,我们需要添加Config字段,以便将配置传递给Follower。相同的,我们需要增加*OpTypeConfig*类型来表示当前Op结构体是配置类型。
type Op struct {
// Your definitions here.
// Field names must start with capital letters,
// otherwise RPC will break.
Type string
Key string // OpTypeGet, OpTypePut, OpTypeAppend
Value string // OpTypeGet, OpTypePut, OpTypeAppend
ClerkID int64
ReqId int64
Config shardctrler.Config // OpTypeConfig
}
在handleOperation方法中,也要增加配置类型的处理逻辑,如下:
switch op.Type {
case OpTypeGet:
val, err = kv.db.Get(op.Key)
case OpTypePut:
val, err = kv.db.Put(op.Key, op.Value)
case OpTypeAppend:
val, err = kv.db.Append(op.Key, op.Value)
case OpTypeConfig:
err = kv.UpdateConfig(op.Config)
}
updateConfig方法的实现如下:
func (kv *ShardKV) UpdateConfig(newCfg shardctrler.Config) Err {
if kv.config.Num >= newCfg.Num {
DPrintf("[Server%d-%d] Config Num[%d] >= New Config Num[%d], Do not need to Update", kv.gid, kv.me, kv.config.Num, newCfg.Num)
return OK
}
if newCfg.Num-kv.config.Num != 1 {
return ErrWrongConfigNum
}
if newCfg.Num == 1 {
DPrintf("[Server%d-%d] Config is NIL, Apply Config, Update :[%v]", kv.gid, kv.me, newCfg)
kv.config = newCfg
return OK
}
kv.config = newCfg
DPrintf("[Server%d-%d] Update Config Success:[%v]", kv.gid, kv.me, newCfg)
return OK
}
监听配置
对于无需每次都查询ShardCtrler,在Lab5B中,任务期望我们以100ms间隔轮询。因此在实现上,我们开启一个协程,每隔100ms获取一次配置,如需要更新配置,则创建Op结构体并发送至Raft。
特别需要注意锁的获取和释放。
func (kv *ShardKV) PollConfig() {
for !kv.killed() {
time.Sleep(100 * time.Millisecond)
if kv.isLeader() {
update := false
kv.mu.Lock()
nextCfg := kv.config.Num + 1
kv.mu.Unlock()
cfg := kv.mck.Query(nextCfg)
kv.mu.Lock()
if cfg.Num > kv.config.Num {
update = true
}
kv.mu.Unlock()
if update {
_, err := kv.opHandler(Op{
Type: OpTypeConfig,
ClerkID: kv.ClerkId,
ReqId: kv.nextId(),
Config: cfg,
})
if err != OK {
DPrintf("[Server%d-%d] Push Config Op Failed, Err: %v", kv.gid, kv.me, err)
}
}
}
}
}
易错点
总结一下易错点,如下:
- 排序算法的稳定性
- 要保证各副本Shard数组的一致性,使用排序时必须保证结果的稳定性。
- map迭代顺序的无序性
- map本身是无序的,若不考虑这点,可能会导致副本Shard数组不一致。
- Group数量与NShard的关系
- 若Group数量大于Nshard,那么必然会存在部分Group无法分配到Shard。
- 更新Config需要由Leader通过Raft同步至各Follower
- 此举才能保证线性一致性。
- 必须按配置编号顺序地更新
- 不然会出现配置不一致的bug,所以每次向ShardCtrler拉取的都是当前cfg编号+1的配置。
Lab5B
这一部分的主要任务是在控制器更改分片时,在副本组之间移动分片,并以提供线性化 k/v 客户端操作的方式进行。Lab5B 附有两个 challenges,分别要求我们实现
- 失效数据的清除(Challenge 1)
- 异步变更配置的 shardkv(Challenge 2)。
我们的目标是实现两个Challenge,因此在设计之初就需要考虑。
配置更新策略
每个Group的配置必须按照严格的版本号顺序处理(C1→C2→C3),这确保了系统状态的一致性和可预测性。
而对于Group内部的更新策略,我最初的考虑是这样的:当需要更新的配置与当前配置的差异不与之前的差异冲突时,就允许更新,即“非冲突diff可接受”的原则。这种做法的优点包括:
- 提高了并发更新的可能性;
- 对于互不影响的配置项变更可以独立进行
但缺点也很明显,实现该策略的复杂性无比巨大,需要考虑多个Group之间的配置同步,而且可能引入难以调试的竞态条件。
于是我转换了策略,即Group必须完全处理完当前配置变更后,才进入下一配置。这种设计也反映了分布式系统设计中的重要原则:有时候更简单的方法虽然看起来效率较低,但实际上能够显著降低出错风险。
Challenge要求已经迁移的分片能立即投入服务,无需等待所有分片迁移完毕。为了满足Challenge的要求,我们需要设置一个Shard状态数组来标明状态,包括Serving、Sending和Receiving。
type ShardStatus uint8
const (
ShardStatusServing ShardStatus = iota // 正在提供服务
ShardStatusSending = iota // 正在发送
ShardStatusReceiving = iota // 正在接收
)
分片迁移策略
假设根据新的配置,某Shard需要从Server1迁移至Server2,那么我们应该如何进行迁移?
网上大多数文章都采用Pull模式,即让Server2主动向Server1发起请求,以获取分片数据。但此方法不能很好的让Server1判断Shard是否迁移完毕,因为Server2主动请求,Server1成功返回数据后,Server1无法确定Server2是否收到数据,因此不能更改自身的状态。那么,Server1就需要主动发送RPC请求至Server2,来判断Server2是否获取数据。
因此,我采用的策略是Push方法,使用Push方法会比较方便的同步Server的Shard状态,发送一次请求即可修改Server1、Server2的Shard状态,时序图如下。
至于两种方法的难易程度,我个人认为两者的难易程度相当。
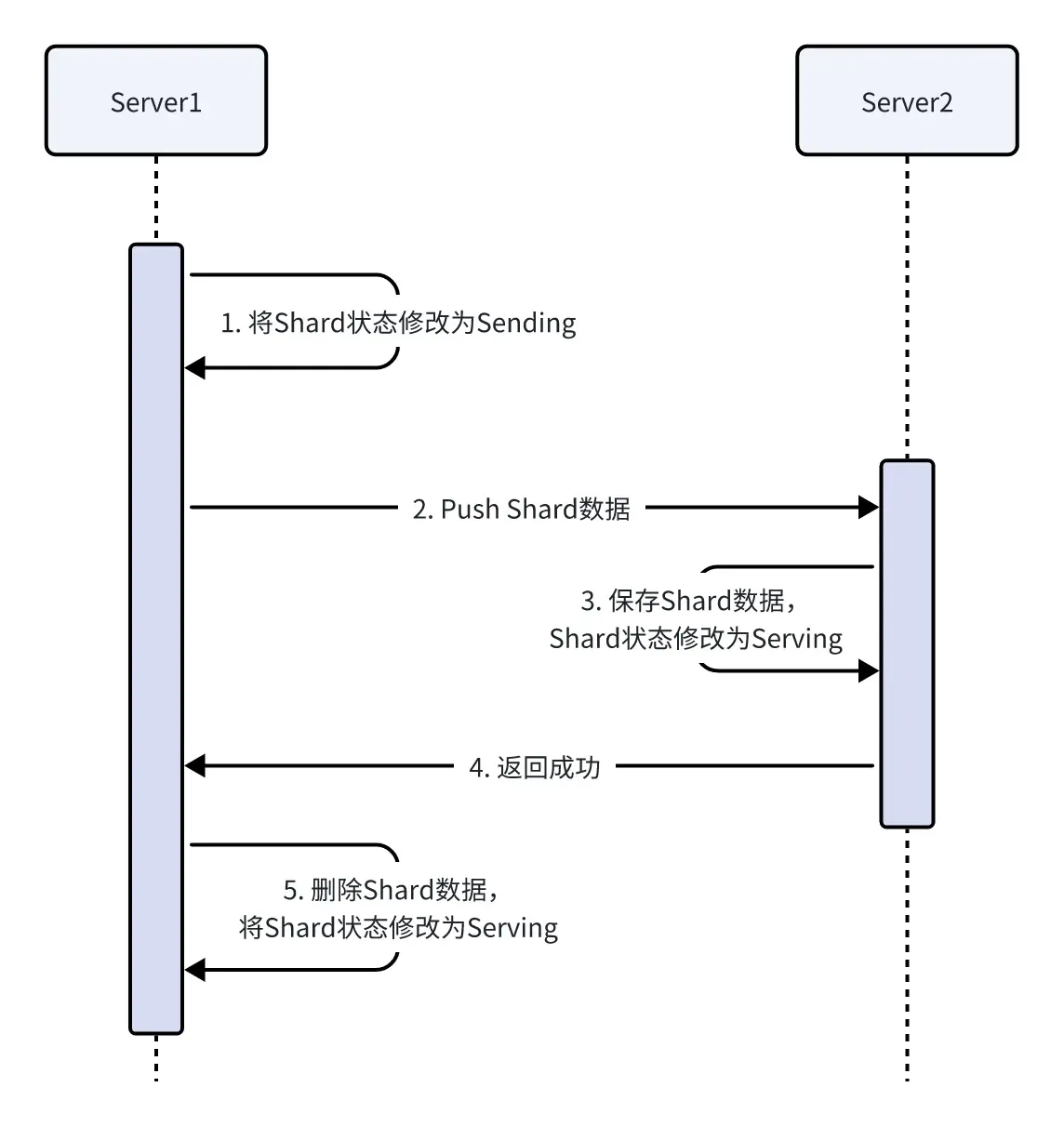
时序图的场景是正常情况,但我们不应该假设网络都是正常的,因此上述2、4步骤很有可能发生错误。
- 步骤2发生错误时,Server1进行重传
- 步骤4发生错误时,Server1进行重传,但Server2需要额外的判断来保证不会出错。
- 当Server1 RPC的ConfigNum 小于 Server2的ConfigNum时,Server返回OK,因为默认数据迁移完毕后才能更新ConfigNum;
- 当Server1 RPC的ConfigNum 等于 Server2的ConfigNum时,检查Shard状态,如果为Serving,则返回OK。
- 当Server1 RPC的ConfigNum 大于 Server2的ConfigNum时,返回Err。
迁移分片后的去重处理
我在实现时,遇到了移动分片后无法去重的问题,如下图所示:
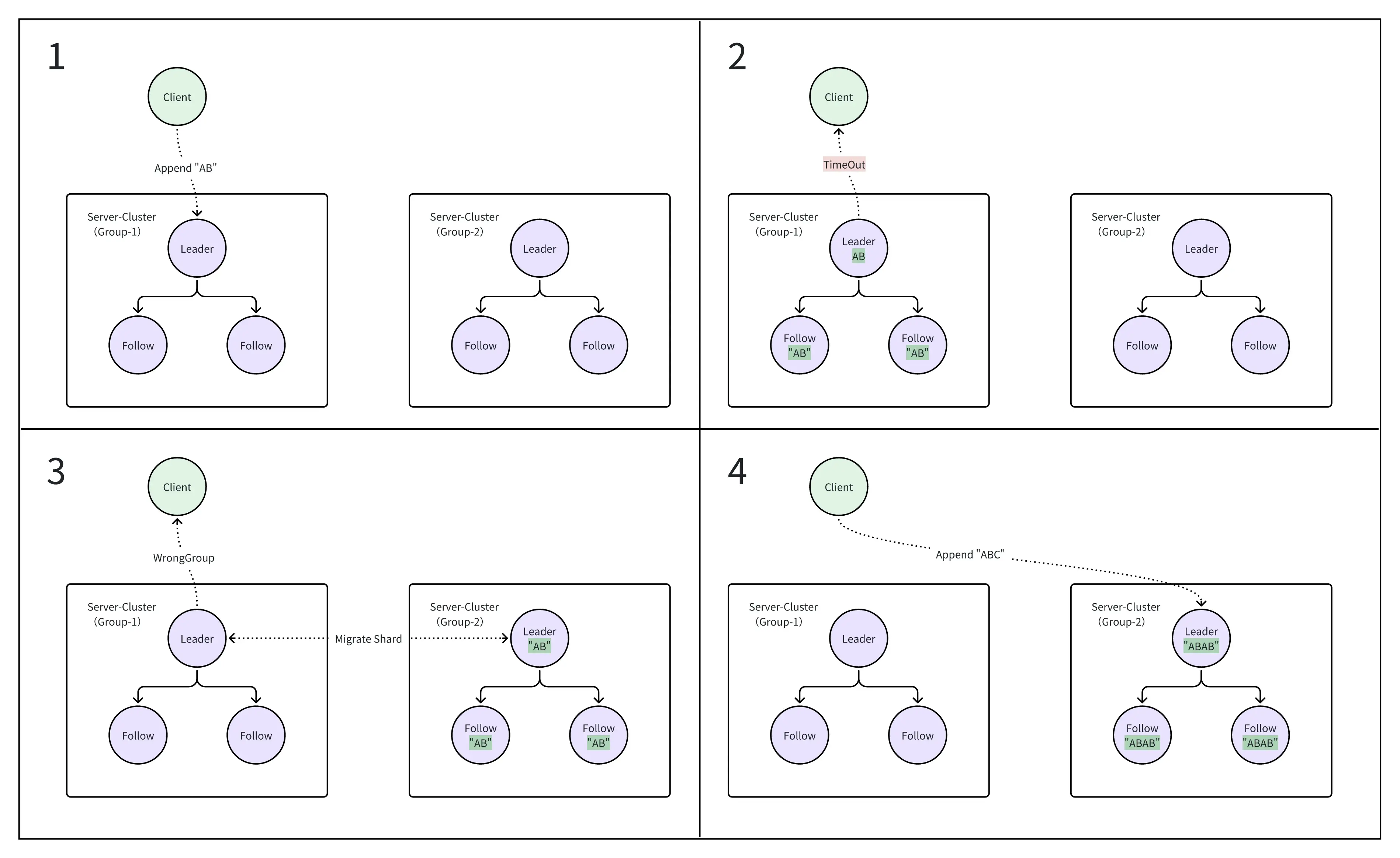
- Client发起
Append "AB"请求,此时请求由G1处理; - G1处理完成,但超时。Client将会重新发起请求;
- Client还未发起请求,发生分片迁移,“AB"迁移至G2处理;
- Client发起Append请求,此时由G2处理,G2重复处理后返回成功信息给Client。
对Client而言,只成功提交了一次,但是对于Server而言成功Append了两次,使得结果出错。
处理方法
在迁移数据时,将已经应用的日志信息AppliedLog也进行迁移,新的Group收到AppliedLog后合并至自身AppliedLog。
分片迁移数据丢失问题
发生分片迁移之后,似乎原先的数据丢失了?分片迁移时似乎没有把最新的数据迁移过来。

问题:G1收到了新的Config,正在发生迁移Shard1至G2,此时Shard1的状态为“sending”,当Shard1由G1发送至G2之后,G1将Shard1的状态改为Serving,当修改Shard1的请求到来时,检查到Shard1的状态为Serving,则修改Shard1了,导致错误!
引起问题的原因如下:
- G1几乎同时更新
Config和Append Shard1消息,Config和Append Shard1都进入Raft等待提交; - G1收到更新Config命令,将Shard1迁移至G2,此时Shard1的状态修改为Sending;
- G1将Shard1迁移完毕,Shard1状态修改为Serving;
- G1收到Raft提交的Append Shard1命令,执行成功后返回至客户端,产生线性不一致问题。
在步骤4中,G1收到Raft提交的Append Shard1命令后,不应该执行命令,应该返回错误。
处理方法
在handleOperation中,除了处理重复值外,还需要判断Shard的分配状态。
核心代码实现
分片迁移
分片迁移的引入会改变
handleOperation方法的逻辑,可以参考仓库代码 。
迁移的RPC的请求响应结构体如下,在请求中,除去必要的Shard、ConfigNum和KVs以外,ClerkId和ReqId用于去重,Applied用于迁移后的去重。
type MigrateShardArgs struct {
Shard int
ConfigNum int
KVs []KV
Applied AppliedLog
ClerkId int64
ReqId int64
}
type MigrateShardReply struct {
ConfigNum int
Err Err
}
以下是MigrateShardRPC方法实现。
func (kv *ShardKV) MigrateShard(args *MigrateShardArgs, reply *MigrateShardReply) {
if !kv.isLeader() {
DPrintf("[Server%d-%d] MigrateShard Shard:[%d] not Leader", kv.gid, kv.me, args.Shard)
reply.Err = ErrWrongLeader
return
}
kv.mu.Lock()
reply.ConfigNum = kv.config.Num
if kv.config.Num < args.ConfigNum {
DPrintf("[Server%d-%d] MigrateShard Shard:[%d] Current ConfigNum:[%d] < ConfigNum:[%d]",
kv.gid, kv.me, args.Shard, kv.config.Num, args.ConfigNum)
reply.Err = ErrWrongConfigNum
kv.mu.Unlock()
return
}
if kv.config.Num > args.ConfigNum {
DPrintf("[Server%d-%d] MigrateShard Shard:[%d] Current ConfigNum:[%d] > ConfigNum:[%d]",
kv.gid, kv.me, args.Shard, kv.config.Num, args.ConfigNum)
reply.Err = OK
kv.mu.Unlock()
return
}
if kv.ShardsStatus[args.Shard] == ShardStatusServing {
DPrintf("[Server%d-%d] MigrateShard Shard:[%d] Already Serving", kv.gid, kv.me, args.Shard)
reply.Err = OK
kv.mu.Unlock()
return
}
kv.mu.Unlock()
op := Op{
Type: OpTypeAddShard,
ClerkID: args.ClerkId,
ReqId: args.ReqId,
Shard: args.Shard,
ShardData: args.KVs,
ConfigNum: args.ConfigNum,
AppliedLog: args.Applied,
}
_, err := kv.opHandler(op)
if err == OK {
DPrintf("[Server%d-%d] MigrateShard Shard:[%d] Success", kv.gid, kv.me, args.Shard)
}
reply.Err = err
}
SendShard有感知到自身Shard发生变化的Leader主动调用,将Shard数据发送至新的Server。只有当RPC响应成功后,才会将数据库中的Shard数据删除。
func (kv *ShardKV) SendShard(shard, configNum int, applied AppliedLog, reqId int64) {
if !kv.isLeader() {
DPrintf("[Server%d-%d] SendShard %d not Leader", kv.gid, kv.me, shard)
return
}
var reply MigrateShardReply
args := MigrateShardArgs{
Shard: shard,
ConfigNum: configNum,
Applied: applied,
KVs: nil,
ClerkId: kv.ClerkId,
ReqId: reqId,
}
kv.mu.Lock()
args.KVs = kv.db.GetByShard(shard)
gid := kv.config.Shards[shard]
servers, ok := kv.config.Groups[gid]
if !ok {
kv.mu.Unlock()
return
}
kv.mu.Unlock()
for i := range servers {
srv := kv.make_end(servers[i])
DPrintf("[Server%d-%d] SendShard %d To %s", kv.gid, kv.me, shard, servers[i])
ok = srv.Call("ShardKV.MigrateShard", &args, &reply)
if !ok {
DPrintf("[Server%d-%d] SendShard %d RPC failed", kv.gid, kv.me, shard)
continue
}
switch reply.Err {
case OK:
DPrintf("[Server%d-%d] SendShard %d To %s Success", kv.gid, kv.me, shard, servers[i])
op := Op{
Type: OpTypeRemoveShard,
ClerkID: args.ClerkId,
ReqId: args.ReqId,
Shard: shard,
ConfigNum: configNum,
}
_, err := kv.opHandler(op)
if err != OK {
DPrintf("[Server%d-%d] handle Op failed, Err: %s", kv.gid, kv.me, err)
} else {
DPrintf("[Server%d-%d] SendShard %d Success", kv.gid, kv.me, shard)
}
case ErrWrongLeader:
continue
default:
DPrintf("[Server%d-%d] SendShard %d failed,Err:%s", kv.gid, kv.me, shard, reply.Err)
}
}
}
分片监听
同理,我们启动一个协程,每50ms监听一次Shard状态,如果存在需要Sending的Shard,则主动发送RPC请求。
func (kv *ShardKV) ShardWatcher() {
for !kv.killed() {
time.Sleep(50 * time.Millisecond)
if !kv.isLeader() {
continue
}
kv.mu.Lock()
if kv.config.Num == 0 {
kv.mu.Unlock()
continue
}
for shard, status := range kv.ShardsStatus {
if status == ShardStatusSending {
DPrintf("[Server%d-%d] ShardWatcher is Preparing to Send Shard", kv.gid, kv.me)
kv.NextReqId++
go kv.SendShard(shard, kv.config.Num, kv.applied.Copy(), kv.NextReqId)
}
}
kv.mu.Unlock()
}
}
易错点
- 只有所有Shards不存在处于Send的状态时,可以更新Config;
- 迁移分片后要保证幂等性;
- 旧配置的Server不允许处理新配置的请求。