
我构建了一套通用的异步任务调度系统。它不仅能满足典型调度系统的业务逻辑,更具备高度的可扩展性和可维护性。
前言
在现代业务系统中,异步任务处理是不可或缺的一环。尤其在面临诸如文档解析、消息队列消费等耗时操作时,将这些任务从主业务流程中解耦,进行独立异步处理,能够显著提升系统响应速度和用户体验。
一个典型的场景便是文档解析系统,任务往往由唯一的文件ID与文件版本共同标识。
设计此类系统并非易事,我们需要考量多重复杂逻辑,例如:
- 版本冗余处理:如何应对同任务多次发起或过低版本请求?
- 任务生命周期管理:解析超时、失败后的状态流转与重试机制。
- 资源并发限制:如何高效控制同时处理的任务数量,避免系统过载?
- 任务优先级调度:如何确保高优先级任务优先执行,同时避免低优先级任务饥饿?
- 数据一致性与对账:系统异常(如解析服务宕机)后,如何恢复正确状态?
面对这些挑战,我构建了一套通用的异步任务调度系统。它不仅能满足上述需求,更具备高度的可扩展性和可维护性。

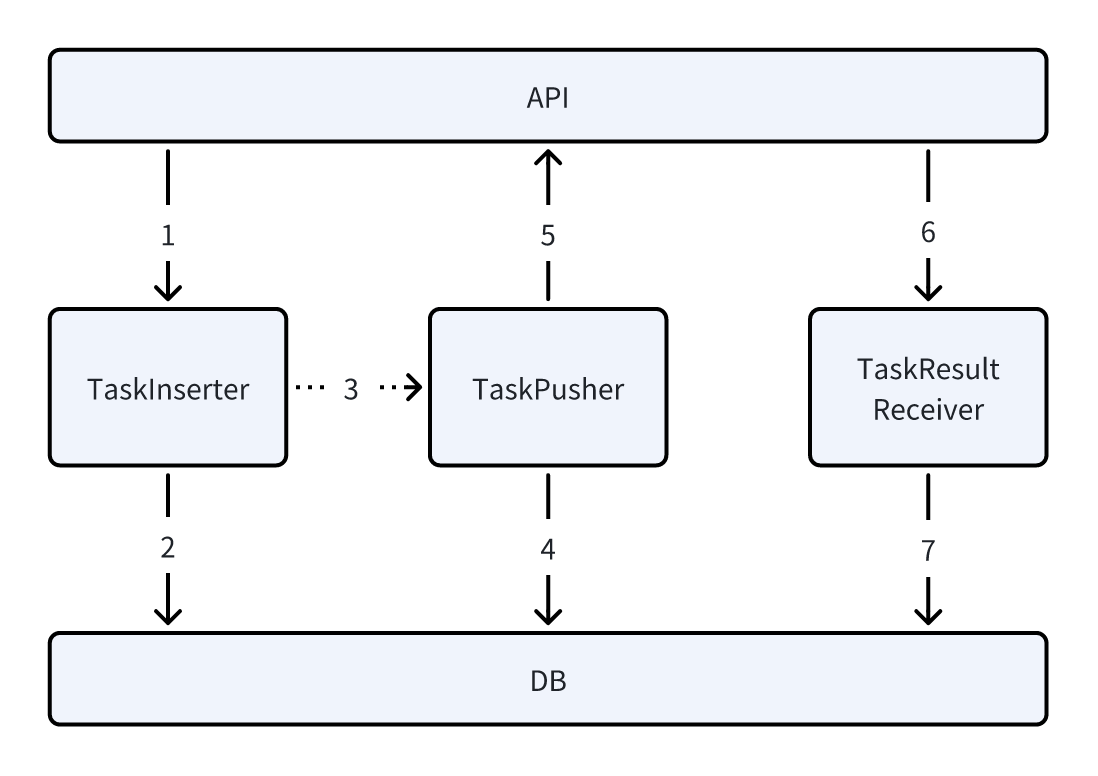
整体架构图
总体而言,任务调度系统基于面向对象的思路设计,遵循清晰的职责分离原则,将核心功能划分为若干领域模块。系统的核心组件包括:
- 任务入库器 (Task Inserter);
- 任务推送器 (Task Pusher) ;
- 任务回调处理器 (Task Result Receiver)。
以及提供基础支撑的
- 并发限制器 (Concurrency Limiter)
- 任务触发器 (Task Trigger)
通过模块间的协作,系统能够实现任务的接收、持久化、调度、并发控制、结果处理以及生命周期管理。
系统主要结构如下图。
领域模型设计
清晰的领域模型是构建稳定系统的基石。我们定义了以下核心数据结构:
任务 Task
考虑到任务的唯一性,我使用task_id、task_version来标记唯一任务。
使用payload来代表任务携带的信息,result表示任务的处理结果。
priority表示任务优先级,使用1表示高优先级,5表示低优先级,其中2~4为预留优先级。
type Task struct{
TaskId int64
TaskVersion int64
Priority int8
Payload []byte
}
任务结果 TaskResult
任务处理完成后,需要一个结构化的方式来封装处理结果,包括处理状态、状态信息及实际结果数据。
type TaskResult struct{
StatusCode int64
StatusMsg string
Result []byte
}
任务状态 TaskStatus
一个任务会经历一系列状态变化,我定义了以下几种核心状态,以精确反映任务在其生命周期中的位置:
- **Pending (待处理):**任务已入库,等待被调度执行。
- **Processing (处理中):**任务已被处理,正在执行。
- **Success (已成功):**任务已成功完成。
- **Failed (已失败):**任务执行失败。
- **Stopped (已结束):**任务生命周期结束,可被清理。
任务状态流转图如下所示:
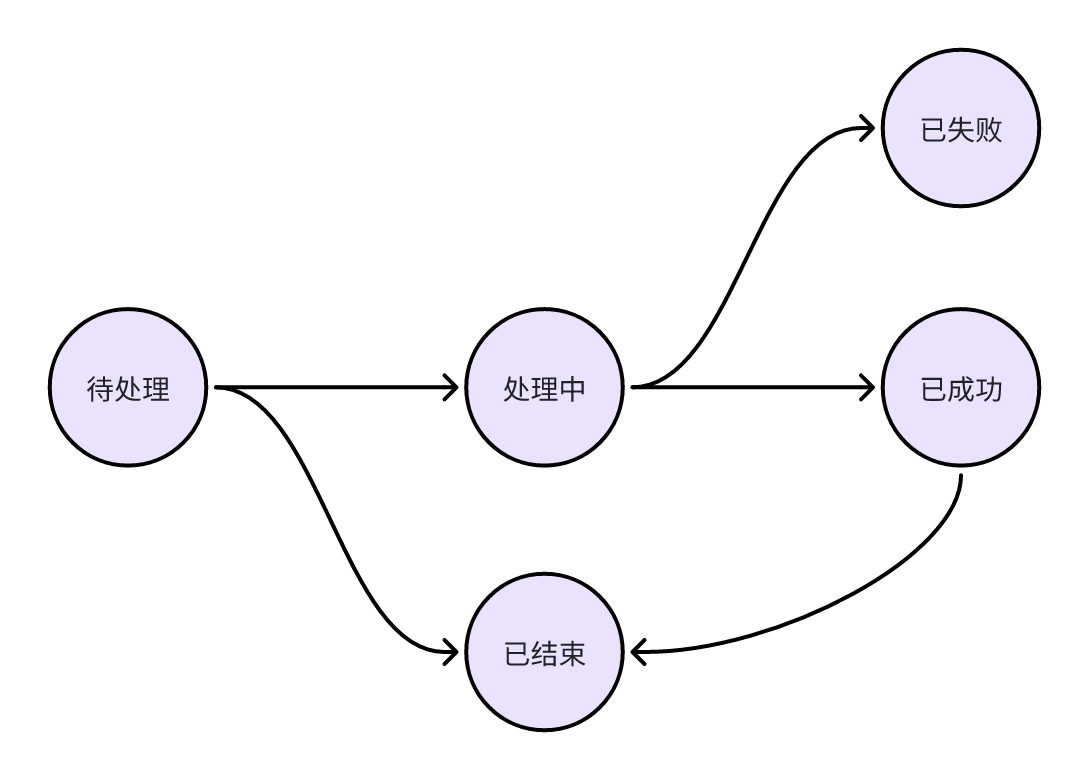
关于 Success 状态转换为 Stopped 的说明:
在我的设计中,Success状态并非任务的终态。处于这种状态的任务,通常会保留一段时间(例如缓存周期24小时),以便后续重复查询。当达到预设的保留时间后,任务状态将转换为 Stopped。
Stopped 状态意味着该任务的生命周期已物理性结束,可以随时被系统清理(即从数据库中删除)。这种设计有助于精细化管理任务的生命周期,平衡数据保留与系统资源消耗。
通用数据表设计
系统采用关系型数据库进行任务的持久化。
| 序号 | 字段名称 | 字段类型 | 字段说明 |
|---|---|---|---|
| 1 | id | bigint | 主键 |
| 2 | task_id | bigint | 任务id |
| 3 | task_version | bigint | 任务版本 |
| 4 | status | int | 任务状态 |
| 5 | create_at | bigint | 创建时间戳 |
| 6 | update_at | bigint | 修改时间戳 |
| 7 | payload | TEXT | 任务载荷(信息) |
| 8 | result | TEXT | 任务处理结果 |
关键优化点提示:
- payload 和 result 字段:考虑到其可能存储大量数据,强烈建议使用 TEXT (对于字符串) 或 BLOB (对于二进制数据) 类型,而非 VARCHAR。对于超出数据库单字段存储限制(如MySQL的4GB)的超大载荷,应考虑将其存储在对象存储(如S3、OSS)中,并在数据库中仅记录对应的Key或URL。
- create_at 和 update_at:使用 BIGINT 存储Unix时间戳(毫秒或纳秒),便于排序和计算,且不受数据库时区配置影响。
- 增加 status_msg 字段用于存储更详细的状态信息,尤其是失败时的错误详情,这对于问题排查至关重要。
业务逻辑设计
TaskInserter
Task Inserter 模块负责接收外部的任务发起请求,并将其持久化到数据库中。在分布式和高并发环境下,它必须具备高度的健壮性以处理各种异常情况,尤其要实现幂等性和版本控制。
处理场景与策略:
- 多次收到相同任务发起请求:通过 task_id 和 task_version 联合唯一索引来判断任务是否已存在。如果已存在且任务状态为Pending、Failed、Stopped,则删除原有任务并新增,否则直接返回现有任务信息,避免重复入库和重复处理。
- 收到低版本的任务发起请求:如果数据库中已存在更高版本的 task_id 任务,则拒绝或忽略当前低版本任务的入库请求。
- 低版本任务未处理完,收到高版本任务:允许入库。系统会优先处理高版本任务(通过 TaskPusher 的优先级策略)。
核心思想:避免无效的任务入库与处理,节约系统资源。
入库流程图如下所示:
graph TD
A[Start: AddTask] --> E[查询同task_id版本>=当前的任务任务]
E --> F[pickLatestTask获取最新任务]
F --> G{是否存在最新任务?}
G -->|否| H[initSave保存任务]
G -->|是| I{最新任务版本比较}
I -->|大于当前版本| J[handleHigherVersionTask]
I -->|等于当前版本| K[handleEqualVersionTask]
%% 高版本任务处理
J --> L{任务状态?}
L -->|Pending/Processing| M[记录日志并返回]
L -->|Success| N[返回]
%% 同版本任务处理
K --> O{任务状态?}
O -->|Processing| P[记录日志并返回]
O -->|Success| Q[返回]
O -->|Pending| R[initSave保存任务]
TaskPusher
Task Pusher 负责从数据库中拉取待处理 (Pending) 的任务,并将其推送至Worker。其关键在于如何有效获取任务以及避免低优先级任务的饥饿。
由“任务推送触发器”控制TaskPusher拉取任务,拉取任务的过程如下图所示。
graph TD
A[TaskPusher] --> E[获取剩余限制任务数restN]
E --> F{restN > 0?}
F -->|否| G[记录日志并返回]
F -->|是| H[通过chooser获取待处理任务]
H --> I{遍历获取的任务}
I -->|每个任务| J[处理任务]
%% handleTask流程
J --> K[增加并发计数]
K --> L{并发计数成功?}
L -->|失败| M[返回错误]
L -->|成功| N[尝试更新任务状态为Processing]
N --> O{状态更新成功?}
O -->|行数为0| P[减少并发计数后返回]
O -->|成功| Q[发送任务]
Q --> R{任务发送成功?}
R -->|成功| S[记录日志后返回]
R -->|失败| T[更新状态为Failed]
T --> U[减少并发计数]
classDef main fill:#e6f7ff,stroke:#333,stroke-width:1px;
classDef branch fill:#f9f2f4,stroke:#333,stroke-width:1px;
classDef subflow fill:#f0f7ee,stroke:#333,stroke-width:1px;
class A main;
class F,O,R branch;
class Q subflow;
防饥饿策略:高/低优先级混合调度
本系统目前仅包含高、低两种优先级(可通过扩展支持更多)。我们采用了一种简单而有效的概率性调度策略来兼顾公平性(对应图中Chooser):
- 80% 的概率执行高优先级任务拉取SQL:
SELECT id FROM tb WHERE status='Pending' ORDER BY priority ASC, id ASC LIMIT N;
这条SQL会优先选择 priority 值最小(最高优先级)的任务,并在优先级相同的情况下,按照 id 升序(即创建时间顺序)选择最老的任务。
- 20% 的概率执行低优先级任务拉取SQL:
SELECT id FROM tb WHERE status='Pending' ORDER BY priority DESC, id ASC LIMIT N;
这条SQL会优先选择 priority 值最大(最低优先级)的任务。
这种方式保证了每次拉取任务的数量都不为0,例如高优先级任务队列为空时,两种情况都会自然地拉取到低优先级任务。
通过这种加权轮询的方式,既保证了高优先级任务能及时得到处理,又确保了低优先级任务有被执行的机会,有效避免了饥饿现象。拉取到的任务会在数据库中立即将其状态更改为 Processing。
TaskResultReceiver
Task Result Receiver 负责接收外部 Worker 处理完成后的任务结果回调。这是任务生命周期中的关键一环,它将影响任务的最终状态及并发控制。
处理流程:
- 接收 Worker 发送的任务处理结果 (包含 task_id, task_version, task_result 等)。
- 根据 task_id 和 task_version 精准定位到数据库中的任务记录。
- 原子性更新任务状态 (Success 或 Failed)、更新 result、status_msg 以及 update_at 字段。
- 仅当数据库状态更新成功后,才通知“任务并发限制器”减少当前 Processing 任务的数量。这确保了计数的准确性,防止在数据库操作失败时导致并发计数出现偏差。
TaskWatcher
Task Watcher 是系统健壮性的重要保障,它以定时任务的形式运行,负责监控并处理任务的异常状态和过期任务的清理。
监控职责:
- Pending 任务超时失败:当任务长时间处于 Pending 状态,超过预设的 PendingExpiredTime,表明该任务可能因某种异常(如推送器故障、无可用Worker等)未能被及时处理。Watcher 会将其状态转变为 Failed。
- Processing 任务超时失败:当任务被 Worker 领取后,长时间处于 Processing 状态,超过预设的 ProcessingExpiredTime,表明Worker可能已宕机、处理卡死或网络中断,未能及时回调。Watcher 会将其状态转变为 Failed,并确保 并发限制器 的计数得到修正。
- Success 任务转为 Stopped:当任务成功完成并已达到 SuccessExpiredTime(即其结果缓存期已过),Watcher 会将其状态转变为 Stopped,标记为可清理。
- 定时物理删除过期任务:Watcher 会定期扫描处于 Failed 或 Stopped 状态且 update_at 时间已达到可配置的清理周期(N天) 的任务,将其从数据库中物理删除,释放存储空间。
基础设施设计
任务并发限制器
并发限制器是确保系统稳定运行的关键。它用于控制系统中同时处于 Processing 状态的任务总数,防止任务处理服务过载。
- 存储介质:使用 Redis-String 存储。Value 表示当前处理中的任务数量。Redis 具有原子操作和高性能的特点,非常适合分布式场景下的计数。为确保原子增减值的上下限,需要使用Lua脚本保证Redis命令的原子性。
- 操作:
- 当 TaskPusher 成功将任务状态从 Pending 更新为 Processing 时,通过 Redis 的 INCR 命令原子性地增加计数。在 INCR 前,会检查当前计数是否已达到最大并发限制。
- 当 TaskResult Receiver 成功将任务状态从 Processing 更新为 Success 或 Failed 时,通过 Redis 的 DECR 命令原子性地减少计数。
- 对账机制:为了应对解析服务宕机、异常退出或其他原因导致Redis计数器与数据库实际状态不一致的问题,系统会每隔 T 时间(可配置)与数据库进行一次对账。
- 对账逻辑:统计数据库中 status=‘Processing’ 的任务数量,然后用这个真实数量强制更新Redis Value值。这能够确保即使在极端情况下,并发计数也能及时校准,保证系统长时间运行的稳定性。
任务推送触发器
任务推送触发器负责异步唤醒 Task Pusher 从数据库中拉取并处理任务。
触发时机:
- 任务成功入库后:当 Task Inserter 成功将新任务写入数据库后,立即触发一次 Task Pusher 尝试推送任务。这保证了新任务能够被及时发现并处理。
- 周期性触发:每隔 N 间隔时间(例如:每5秒)触发一次 Task Pusher。这是一个兜底机制,即使事件触发失败也能保证任务被周期性地检测和推送,防止任务堆积。
- 任务成功回调后:当 Task Result Receiver 接收到任务完成回调并更新状态后,也触发一次 Task Pusher。这表示有空闲的并发槽位被释放,可以立即尝试处理新的任务。
更多思考与系统增强
作为一个生产级的任务调度系统,我们还需要考虑以下高级特性与优化。
重试
在许多业务场景下,任务失败后需要进行重试。本方案可以通过以下方式扩展支持重试:
- 数据库字段:在 task_scheduler_tasks 表中增加 retry_count (当前重试次数) 和 max_retries (最大重试次数) 字段。
- 失败状态处理:当任务失败 (Failed) 且 retry_count < max_retries 时:
- 不直接转为 Stopped。
- 将 retry_count 增加1。
- 根据预设的重试策略(立即重试、固定间隔重试、指数退避重试等),将任务状态重新置为 Pending,并根据重试策略更新 create_at 或设置一个 next_retry_time。
- 可以为重试任务设置一个稍低的优先级,避免重试任务阻塞新任务。
- 专属TaskPusher:对于重试任务,可以考虑为其设置专属TaskPusher,实现资源隔离。
多优先级
当任务优先级大于两种时,简单的概率策略可能不足。可以考虑更复杂的调度算法:
- 权重队列:为每个优先级分配不同的权重,根据权重比例从相应队列中拉取任务。
- 调度算法:在每次拉取任务时,通过加权随机算法选择要读取的优先级区间。
但需要关注某权重任务为空的情况,出现该情况时,建议立即更换权重。
可伸缩性
为应对快速变化的业务,可伸缩性极其重要,为避免多实例造成影响。
- 任务并发限制器:多个实例共用限制器,避免任务处理的并发数过大。
- 定时任务:定时任务增加分布式锁,避免多个定时任务同时执行。
- 数据库原子性:使用update原子操作避免相同任务被多实例发送。
可观察性
一个生产级系统必须具备完善的可观察性,根据项目上线后的经验,建议添加以下观察项:
- 日志 (Logging) :详细记录任务的生命周期、状态变更、错误信息、性能数据。
- 指标 (Metrics) :暴露关键指标到监控系统 (如Prometheus):
Pending/Processing/Success/Failed任务数量。- 任务处理耗时分布。
- 并发限制器当前值。
- 链路追踪 (Tracing) :系统中各模块均异步处理,容易将任务由入库到完成的链路打断,导致问题排查困难,建议补齐完成链路。
总结
本文详细阐述了一个异步任务调度系统设计,涵盖了核心领域模型、数据库设计、业务逻辑处理以及关键基础设施。通过引入任务版本管理、优先级调度、并发限制、超时监控与自动清理等机制,我们构建了一个健壮、高效且具备高可扩展性的异步任务处理平台。
该系统能够有效解决异步任务管理面临的诸多挑战,确保任务的可靠执行与资源的合理利用。